I had heard of LevelDB a while ago, but this time, on a whim, I went through the code with some reference materials, and it really lives up to its reputation. Whether you are interested in storage, want to use C++ elegantly, or want to learn how to architect a project, I highly recommend taking a look. Not to mention that the authors are Sanjay Ghemawat and Jeff Dean.
If I don’t write something after reading through it once, given my memory, I’ll surely forget it soon. So I wanted to write something about the wonders of LevelDB, but I didn’t want to take the usual approach: starting with an architectural overview and ending with module analysis. While reading the code, I kept thinking about where to start writing. When I was just finishing up, what impressed me most were actually all the exquisite data structures in LevelDB: tailored to the scenario, built from scratch, appropriately trimmed, and precisely coded. Why not start the LevelDB series with these little corner pieces?
This series mainly wants to share three classic data structures commonly used in engineering in LevelDB: the Skip List used for fast read/write to the memtable, the Bloom Filter used for fast filtering of sstables, and the LRUCache used for partially caching sstables. This is the third article, on LRUCache.
Introduction
LRU is a data structure commonly seen in engineering, often used in caching scenarios. In recent years, LRU has also become a hot interview question, first because it is widely used in engineering, second because the code volume is relatively small, and third because the data structures involved are very typical. There is a corresponding problem on LeetCode: lru-cache. Compared to real-world scenarios, the problem has been simplified: essentially, it requires maintaining a time-ordered key-value collection, where both keys and values are integers. The classic solution is to use a hash table (unordered_map) and a doubly linked list; the hash table solves the indexing problem, and the doubly linked list maintains the access order. Here is a solution I wrote at the time, which is characterized by using two helper functions and being able to return the node itself to support chaining, thereby simplifying the code.
Returning to the LevelDB source code, as an industrial-grade product, what optimizations and changes have been made to its LRUCache? Let’s break down the LRUCache used in LevelDB together and see what the differences are.
This article first clarifies how LRUCache is used, then gives an overview of the implementation ideas of LRUCache, and finally details the implementation of the relevant data structures.
Author: Muniao’s Miscellany https://www.qtmuniao.com/2021/05/09/levedb-data-structures-lru-cache/, please indicate the source when reposting
Cache Usage
Before analyzing the implementation of LRUCache, let’s first understand how LRUCache is used to clarify the problems it needs to solve. Based on this, we can understand why it is implemented this way, and even further, discuss whether there is a better implementation.
First, let’s look at the exported interface Cache in LevelDB:
1 | // Insert a key-value pair (key, value) into the cache, |
Based on the above interface, the cache-related requirements for LevelDB can be summarized as:
- Multi-threaded support
- Performance requirements
- Data entry lifecycle management
Using a state machine to represent the lifecycle of an Entry in the Cache is as follows:
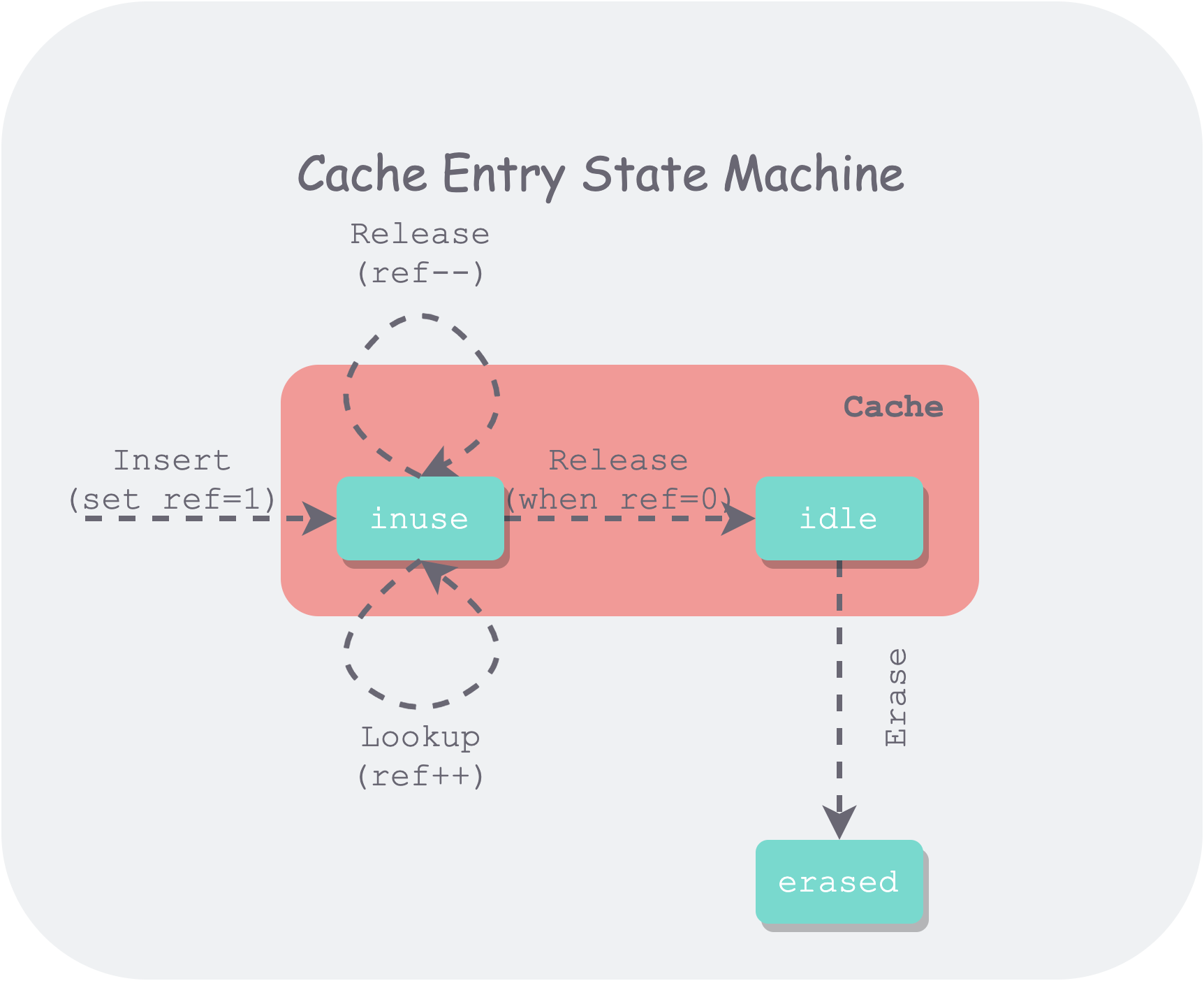 leveldb-entry-lifecycle.png
leveldb-entry-lifecycle.png
It can be seen that this state machine is somewhat more complex than the one in LeetCode. First, multi-threaded references have been added, and second, it is necessary to distinguish between referenced (inuse) and idle states.
Multiple threads can insert and reference the same entry through Insert and Lookup, so the cache needs to maintain the reference count for each entry. Only entries with a reference count of 0 will enter an evictable (idle) state. All evictable entries are sorted by LRU order, and when usage exceeds capacity, the least recently used entry will be evicted based on this order.
In addition, inter-thread synchronization and mutual exclusion are required to ensure that the Cache is thread-safe. The simplest method is to use a single lock for the entire Cache, but this would cause serious contention among multiple threads, leading to performance issues.
Next, let’s see how LevelDB’s LRUCache solves these problems.
Overview
Overall, LevelDB’s LRUCache also uses the implementation idea of a hash table and a doubly linked list, but with some differences:
- A minimal custom hash table using an array + linked list to handle collisions, facilitating control over allocation and resizing.
- Multi-threaded support. To improve concurrency, sharding is introduced; to distinguish whether it is referenced by a client, two doubly linked lists are introduced.
The entire code is quite concise, and the ideas are relatively straightforward.
Custom Hash Table
In LevelDB, the hash table keeps the number of buckets as a power of two, thereby using bitwise operations to quickly compute the bucket position from the key’s hash value. The method to get the bucket handle from the key’s hash value is as follows:
1 | LRUHandle** ptr = &list_[hash & (length_ - 1)]; |
During each adjustment, the number of buckets is doubled when expanding and halved when shrinking, and all data entries need to be rehashed.
Two Linked Lists
LevelDB uses two doubly linked lists to store data. All data in the cache is either in one linked list or the other, but cannot exist in both at the same time. These two linked lists are:
- in-use list. All data entries (a kv item) currently being used by clients are stored in this list. This list is unordered, because when capacity is insufficient, entries in this list definitely cannot be evicted, so there is no need to maintain an eviction order.
- lru list. All entries no longer used by clients are placed in the lru list. This list is ordered by most recent usage time. When capacity is insufficient, the least recently used entry in this list will be evicted.
It is also worth mentioning that the linked list nodes used in the hash table to handle collisions and the nodes in the doubly linked list use the same data structure (LRUHandle), but different pointer fields in LRUHandle are used when chaining them together.
Data Structures
The LRUCache implementation mainly involves four data structures: LRUHandle, HandleTable, LRUCache, and ShardedLRUCache. The organization of the first three is as follows:
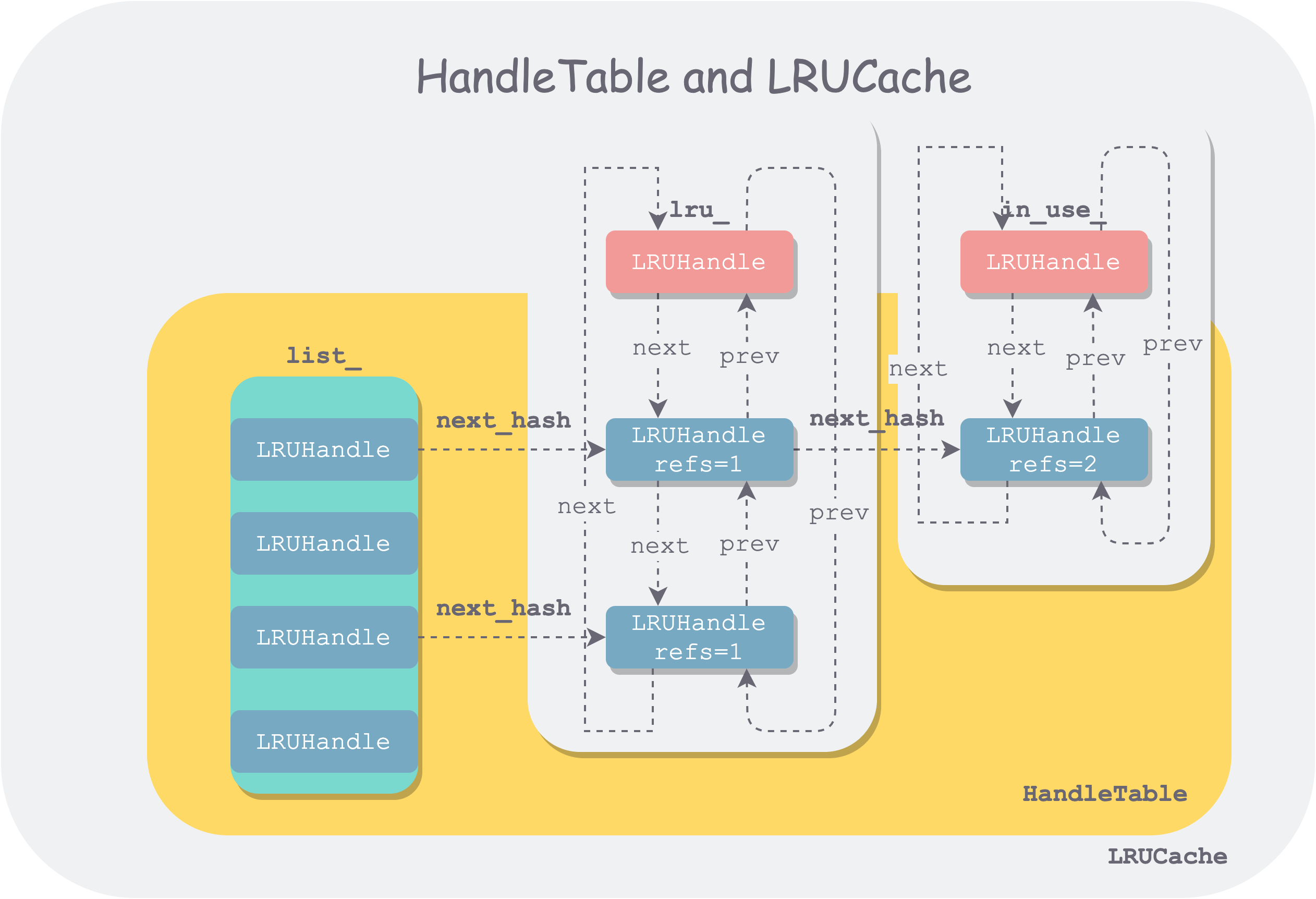 lru-cache-architecture.png
lru-cache-architecture.png
ShardedLRUCache consists of a set of LRUCaches, each LRUCache acting as a shard and also a locking granularity. They all implement the Cache interface. The schematic below only shows 4 shards; in the code there are 16.
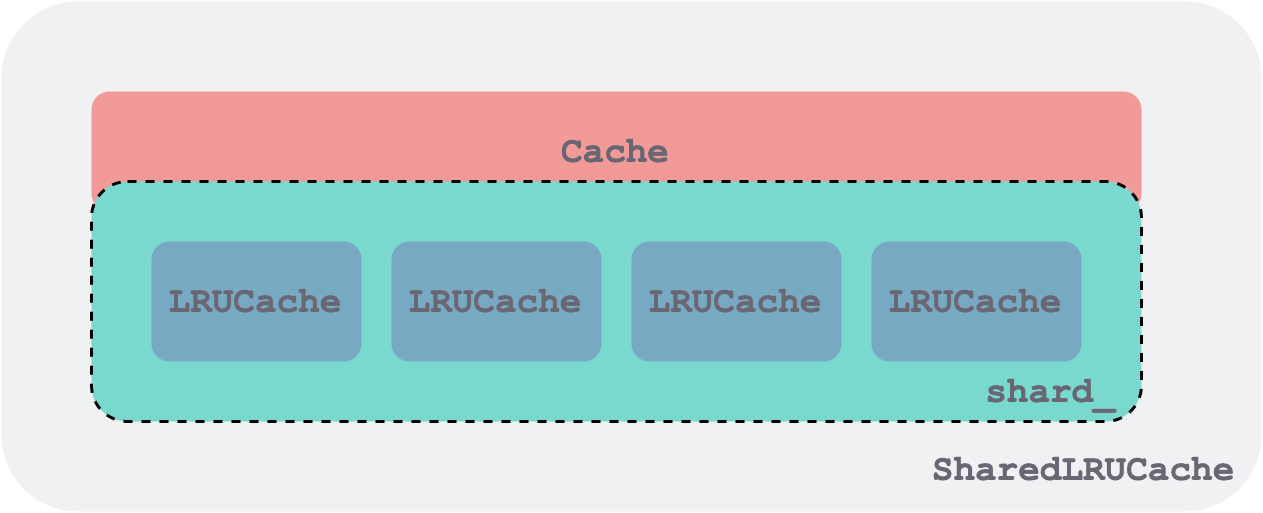 shared-lru-cache.png
shared-lru-cache.png
LRUHandle — The Basic Data Unit
LRUHandle is the basic building block of the doubly linked list and the hash table, and it is also the basic unit for caching and operating data entries. Its structure is as follows:
1 | struct LRUHandle { |
Pay special attention: the meaning of refs in LRUHandle is different from the ref in the state machine diagram in the previous subsection. In the LevelDB implementation, the Cache’s own reference is also counted as a reference. Therefore, during Insert, refs is set to 2: one for the client reference and one for the LRUCache reference. refs==1 && in_cache means that the data entry is only referenced by LRUCache.
This design may look a bit awkward at first, but after thinking about it, it feels quite natural and fitting.
HandleTable — Hash Table Index
Bitwise operations are used to route keys, and linked lists are used to handle collisions; the implementation is fairly straightforward. The nodes in the linked list are unordered, so every lookup requires a full linked list traversal.
Among the functions, FindPointer is worth mentioning. This lookup helper function uses a double pointer, which is quite concise when adding or deleting nodes, though it may be a bit hard to understand at first. In a typical implementation, when adding or deleting nodes, we need to find their predecessor node. However, in fact, add and delete operations only use the next_hash pointer of the predecessor node:
- Deletion: modifies the
next_hashpointer. - Insertion: first reads
next_hashto find the next link in the chain, attaches it after the node to be inserted, and then modifies the predecessor node’snext_hashpointer.
Since the essence only involves reading and writing the next_hash pointer of the predecessor node, returning a pointer to the predecessor node’s next_hash pointer is a more concise approach:
1 | LRUHandle** FindPointer(const Slice& key, uint32_t hash) { |
This function first uses the hash value to locate a bucket via bitwise operation. Then it iterates through the nodes in that bucket one by one:
- If the node’s hash or key matches, it returns the double pointer to that node (the pointer to the predecessor node’s next_hash pointer).
- Otherwise, it returns the double pointer of the last node in that linked list (boundary case: for an empty linked list, the last node is the bucket head).
Since what is returned is the address of the predecessor node’s next_hash, during deletion, you only need to change this next_hash to the successor node’s address of the node to be deleted, and then return the node to be deleted.
1 | LRUHandle* Remove(const Slice& key, uint32_t hash) { |
During insertion, the FindPointer function is also used to find the next_hash pointer of the tail node in the linked list of the bucket to be inserted into. For the boundary condition of an empty bucket, it will find the empty head node of the bucket. Then it needs to determine whether this is a new insertion or a replacement. If it is a replacement, the replaced old node is returned. Below is a schematic diagram of inserting a new node:
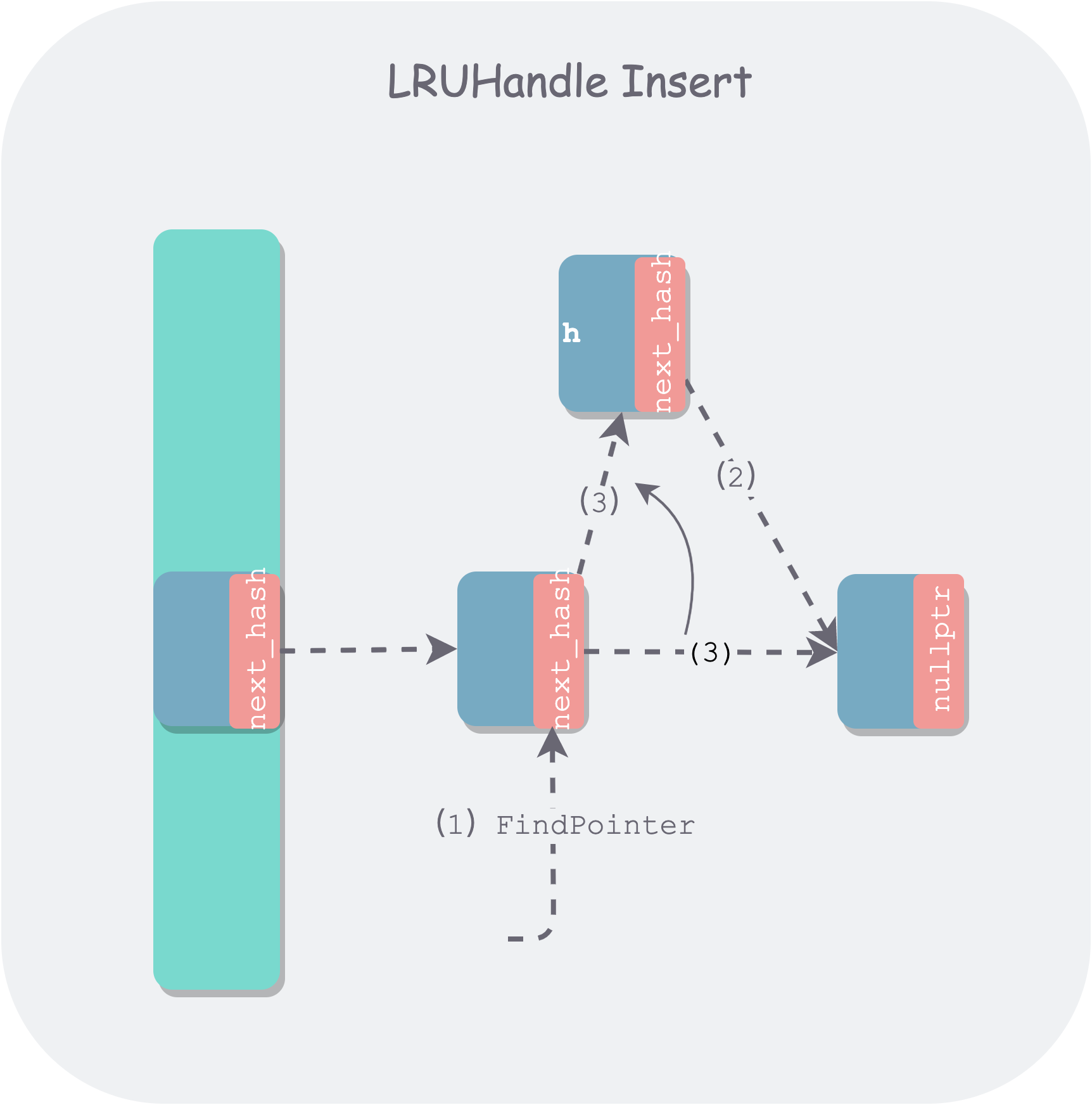 leveldb-table-insert.png
leveldb-table-insert.png
If it is a newly inserted node, the total number of nodes will increase. If the total number of nodes becomes greater than a certain threshold, in order to maintain the performance of the hash table, a resize is needed to increase the number of buckets, while rehashing all nodes. The threshold chosen by LevelDB is length_ — the number of buckets.
The resize operation is quite heavy, because all nodes need to be rehashed, and to ensure thread safety, a lock is required, which will make the hash table unavailable for a period of time. Of course, sharding has already reduced the number of nodes in a single shard, but if the sharding is uneven, it can still be quite heavy. Here a progressive migration method is mentioned: Dynamic-sized NonBlocking Hash table, which can amortize the migration time, somewhat similar to the evolution of Go GC.
LRUCache — Hash Table Index + Doubly Circular Linked List
After removing the functions included in the exported interface Cache, the LRUCache class is simplified as follows:
1 | class LRUCache { |
It can be seen that this implementation has the following characteristics:
- Two doubly linked lists are used to divide the entire cache into two disjoint sets: the
in-uselist of entries referenced by clients, and thelru_list of entries not referenced by any client. - Each doubly linked list uses an empty head pointer to facilitate handling boundary cases. And the
prevpointer of the list head points to the newest entry, while thenextpointer points to the oldest entry, thereby forming a doubly circular linked list. usage_is used to represent the current usage of the cache, andcapacity_represents the total capacity of the cache.- Several basic operations are abstracted:
LRU_Remove,LRU_Append,Ref,Unrefas helper functions for reuse. - Each
LRUCacheis guarded by a lockmutex_.
With an understanding of all fields, as well as the previous state machine, the implementation of each function should be relatively easy to understand. Below, instead of listing all function implementations one by one, only the relatively complex Insert is annotated and explained:
1 | Cache::Handle* LRUCache::Insert(const Slice& key, uint32_t hash, void* value, |
ShardedLRUCache — Sharded LRUCache
The purpose of introducing ShardedLRUCache is to reduce lock granularity and improve read/write parallelism. The strategy is quite concise — using the first kNumShardBits = 4 bits of the key hash value as the shard routing, which can support kNumShards = 1 << kNumShardBits 16 shards. The function to calculate the shard index from the key’s hash value is as follows:
1 | static uint32_t Shard(uint32_t hash) { return hash >> (32 - kNumShardBits); } |
Since both LRUCache and ShardedLRUCache implement the Cache interface, ShardedLRUCache only needs to route all Cache interface operations to the corresponding Shard. Overall, ShardedLRUCache doesn’t have much logic and is more like a Wrapper, so I won’t go into detail here.
References
- LevelDB cache code: https://github.com/google/leveldb/blob/master/util/cache.cc
- LevelDB handbook cache system: https://leveldb-handbook.readthedocs.io/zh/latest/cache.html#dynamic-sized-nonblocking-hash-table

