 6.824-schedule.png
6.824-schedule.png
MIT finally released the lecture videos on YouTube this year. I had followed about half of this course before, and this year I plan to watch the videos and take some notes. The course is structured around the fundamentals of distributed systems—fault tolerance, replication, and consistency—and uses carefully selected industrial-strength system papers as the main thread, supplemented with extensive reading materials and well-crafted labs, bridging academic theory and industrial practice. It is truly an excellent course on distributed systems. Course videos: YouTube, Bilibili. Course materials: 6.824 homepage. This post covers the sixth lecture, the first part of the Raft paper lecture, mainly summarizing several types of fault tolerance and leader election in Raft.
Author: 木鸟杂记 https://www.qtmuniao.com/2020/05/09/6-824-video-notes-6-fault-tolerate-raft-1/, please cite the source when reposting
Fault Tolerance
State machine replication: State machine replication
Fault-Tolerance Patterns
We have learned about the following fault-tolerance patterns:
- Computation redundancy: MapReduce, but all computation is scheduled by a single Master.
- Data redundancy: GFS, which also relies on a single Master to select primaries among multiple replicas.
- Service redundancy: VMware-FT relies on a single TestAndSet operation.
It can be seen that they all rely on a single component to make some critical decisions. The advantage of doing so is that the single component does not need a consensus algorithm and will not produce inconsistency; the disadvantage is that this component becomes a single point in the system. Of course, the above systems have compressed the single-point problem into a very small part. Next, we will further use a consensus algorithm—Raft—to tackle this final hard problem.
Split Brain
The biggest problem in consensus algorithms is how to avoid Split Brain.
So how does Split Brain arise, and why is it so harmful?
Suppose we want to replicate a test-and-set service. Test-and-set, in short, is a lock service. When multiple clients request the service simultaneously, only one of them can pass the Test (check if it is 0), acquire the lock, and set the server state to 1; other clients will fail the test and cannot acquire the lock.
Consider the following four system roles: [C1, C2, S1, S2], where S1 and S2 form a dual-replica, fault-tolerant system, and C1 and C2 are clients using this system. Suppose C1 can communicate with S1 but is disconnected from S2. In the case where only S1 is available, can the system provide normal service to C1?
- If S2 has really crashed, the system should work normally in the absence of S2; otherwise, the system cannot be called fault-tolerant.
- If S2 has not crashed but is disconnected from C1, the system should not provide service to C1, because S2 may be serving C2. If S1 is allowed to serve C1 at the same time, it will cause system state inconsistency and thus service errors: both C1 and C2 acquire the lock.
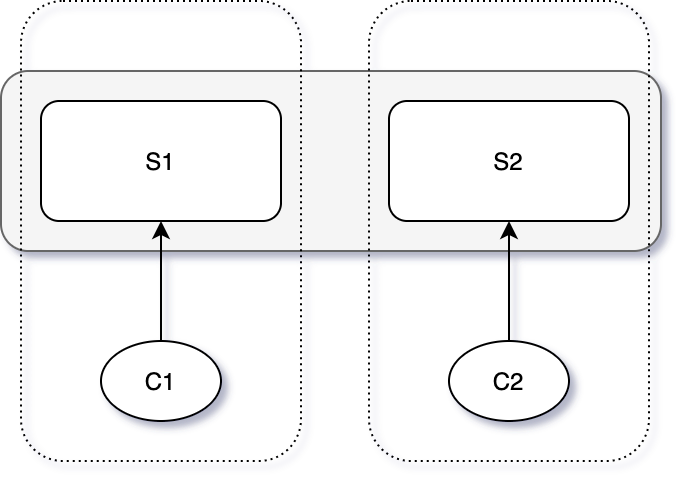 split-brain
split-brain
In this case, we face a dilemma:
- Either do not provide fault-tolerance guarantees, even though we are using dual-replica servers.
- Or still respond to client requests, but do not guarantee consistency because Split Brain may occur.
But the problem is that server S1 cannot distinguish whether S2 is crashed (“server crashed”) or there is a network failure (“network broken”). Because in both cases, what S1 sees is the same: requests to S2 receive no response. S1 can communicate with C1, and S2 can communicate with C2; but S1+C1 cannot receive responses from S2+C2. We call this situation a network partition.
Network partitions may last for a long time, and it may be necessary to introduce an external force (such as an operator) to determine when the network is trustworthy and when the server is trustworthy, in order to break the deadlock. So how can we make fault tolerance automated? The answer is: majority vote.
Majority Vote
The majority vote principle requires the system cluster to contain an odd number of servers, in order to avoid the symmetry dilemma. As in the case above with only two servers, each side insists on its own view, making it difficult to decide which one to follow.
In a system with an odd number of servers, as long as we obtain a majority vote, we can keep the system running normally without falling into a tie deadlock (such as leader election and log entry commitment in Raft). The principle behind the majority vote breaking the deadlock is also simple: it is impossible for more than one partition to simultaneously contain a majority of servers. It should be noted that the majority here refers to the majority of all servers that constitute the system, not the majority of surviving servers.
If the cluster consists of 2f + 1 servers, it can tolerate at most f server failures while still providing service.
Another important property of the majority vote principle is that any two majorities must intersect. For example, in Raft, the voting quorums involved in two successive leader elections must have an intersection; therefore, the next round can obtain the previous term’s decision information (including the previous term and the previous commit information) through the intersecting part.
Around the 1990s, two algorithms emerged: Paxos and View-Stamped Replication (VSR, proposed by MIT), which use the majority vote principle to solve the Split Brain problem. Although the former is more widely known today, the latter is closer to Raft in terms of design philosophy.
Raft Overview
Raft is generally in the form of a library, running on each replica server, managing the replicated state machine, and is mainly responsible for synchronizing the operation log. Based on this, we can further build a reliable KV storage layer, which is mainly responsible for state storage.
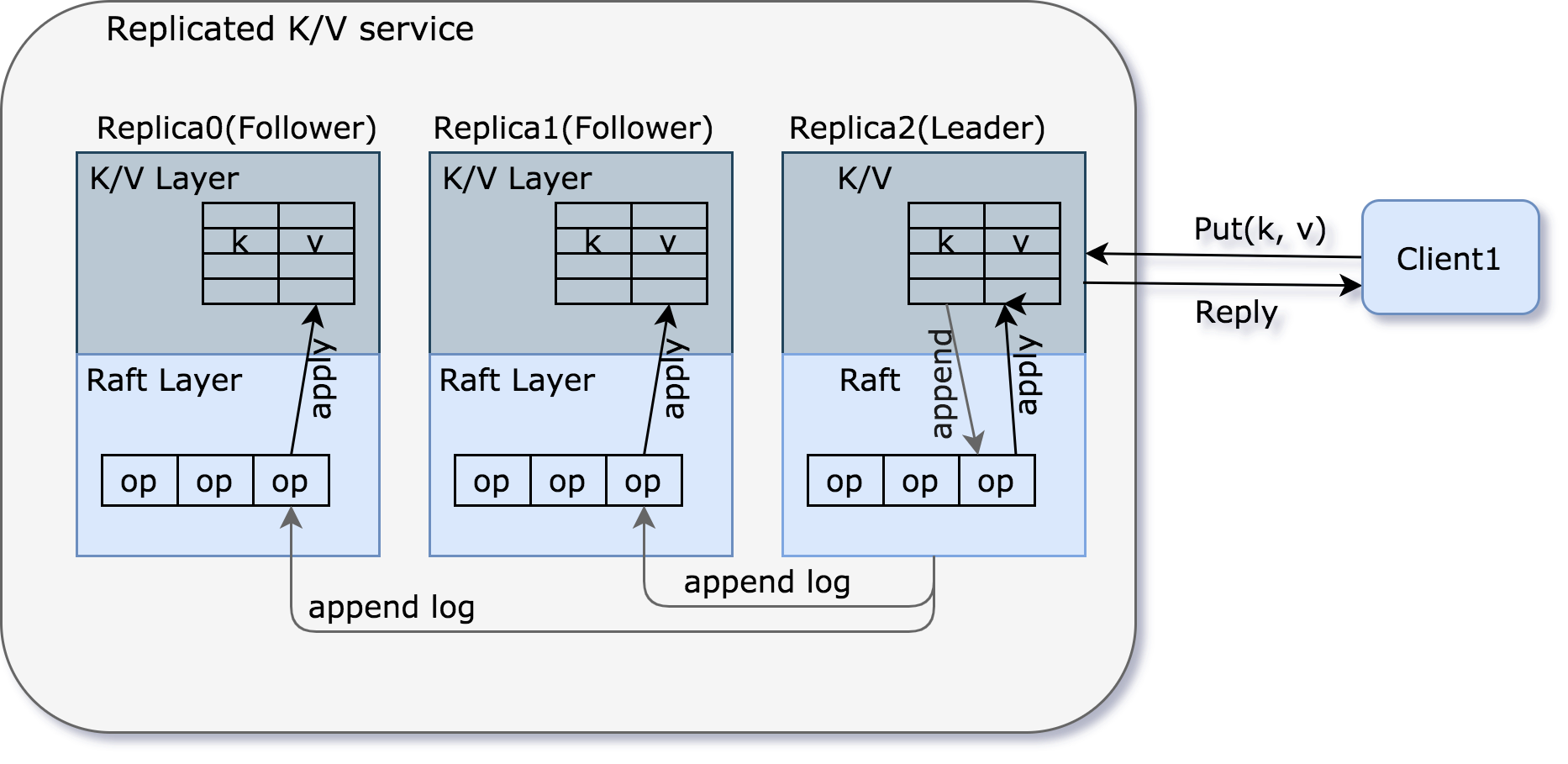 raft-replicated-kv-service
raft-replicated-kv-service
The above figure illustrates a typical interaction flow between a client and a key-value service:
- The client sends a “Put/Get” request to the Leader’s k/v layer.
- The Leader converts the request into a Command (including the action and parameters) and appends it to its local log file.
- The Leader synchronizes the Command to Followers via the AppendEntries RPC.
- Followers append the Command to their local log files.
- The Leader waits for a majority of servers (including itself) to reply.
- After receiving replies from the majority of servers, the Leader commits the corresponding log entry. Committing means that the Command entry will not be deleted, and even if some servers crash, it can still be inherited by the Leader in the next term.
- The Leader executes the Command, applies it to the state machine, and then replies to the client.
- In the next AppendEntries RPC, the Leader piggybacks the commit information (i.e., the offset in the operation log up to which it has committed) to synchronize with each Follower.
- After receiving the commit information, Followers apply the corresponding Command to their state machines.
Operation Log
So why use an operation log to record user request commands?
- The Leader uses the log to determine the order of Commands, enabling all replicas to agree on the order of requests (especially when a large number of requests arrive almost simultaneously) and to maintain log entries in the same order. In this case, the log acts as a locked queue.
- Temporarily store Commands for later submission after commit.
- Save Commands in case the Leader needs to resend them to Followers due to network/server anomalies.
- Reconstruct state after server restart.
Q&A:
-
What if requests come too fast but the log append speed is insufficient?
Therefore, Raft is generally not used as a high-concurrency middleware. Based on this assumption, if this situation is really encountered, the Leader’s request processing speed can be throttled.
-
When each server restarts, it does not immediately execute the Commands in the log, because it does not know which ones have been committed (the commit point is not persisted), and needs the Leader to tell it later.
Raft Interface
Raft mainly provides two interfaces to the KV layer: Start(command) and ApplyMsg->ApplyCh.
Start(command) (index, term, isleader)
Start is only valid when called on the Leader. Its meaning is to let a majority of servers agree on a new log entry (Log Entry, which contains the Command). The main steps are as follows:
- The Leader appends the Command to its local log.
- Sends AppendEntries RPCs to each Follower.
- Start() returns immediately (to the k/v layer) without waiting for replies from each Follower (asynchronous).
- The k/v layer needs to listen on applyCh to determine whether the Command has been committed.
There are three return values:
- index: the position in the log where the Command will be committed.
- term: the current term of the Leader.
- isleader: if this value is false, the client needs to try other servers until it finds the Leader.
ApplyMsg->ApplyCh
ApplyMsg, contains two fields: Command and Index; applyCh, the channel on which the k/v layer listens for ApplyMsgs sent by Raft after commit.
- Every server in the system must send an ApplyMsg to applyCh for every committed log entry.
- Every server in the system, after obtaining an ApplyMsg, updates the Command in it to its local state machine.
- The Leader is responsible for replying to the client (after the corresponding log entry is committed).
At a certain moment, the log entries on each server in the system may not be completely consistent. For example, if the Leader crashes while synchronizing a log entry, then the Leader and some Followers have already appended that log entry, while other Followers have not received it. At this point, the log entries on each server in the system have diverged.
But the good news is that all servers’ log entries will eventually be unified by the new Leader.
Leader Election
Speaking of leader election, the first question to think about is: is a Leader necessary? Do we have to have a Leader to complete log synchronization on all servers? The answer is no, for example, Paxos.
So why does Raft adopt the Leader approach? There are many reasons, one of which is that under normal system and network conditions, having a Leader make decisions can make the system more efficient; the client needs at most two requests per operation (the first to find the Leader’s location, the second to send the request to the Leader).
Term
Raft numbers the sequence of Leaders, namely the term:
- A new Leader means a new term.
- A term has at most one Leader, and it is also possible to have no Leader.
- Terms help Followers follow the latest Leader, rather than a Leader who has already stepped down.
Election
When a Follower does not receive the current Leader’s heartbeat within a certain time interval (Raft calls this the election timeout; in the specific implementation, we use an election timer), it increments its own term (because two Leaders are not allowed within one term, so only by first increasing the term count is it possible to be elected as the new Leader in the new term), declares itself a Candidate, votes for itself, and then asks other servers for votes.
It should be noted that:
- This process may cause unnecessary elections. For example, if a server is temporarily disconnected from the Leader and initiates an election after exceeding the election timeout, and then reconnects to the Leader, it will bring the entire cluster into a new term, causing the original Leader to become invalid. Although this approach is sometimes inefficient, it is safe.
- The old Leader may still be alive and consider itself the Leader. For example, if a network partition occurs, the old Leader is partitioned into the minority server partition, while the majority server partition elects a new Leader. The old Leader will still consider itself the Leader and try to exercise Leader functions, such as receiving client requests and trying to synchronize log entries. However, because it is impossible to obtain a majority of responses, it cannot commit and thus cannot reply to the client.
Q&A:
If the network experiences some miraculous failure that only allows one-way communication—that is, the Leader can send heartbeats to Followers, suppressing them from initiating elections; but cannot receive client requests—can Raft still work properly?
Indeed, it cannot, but this problem can be solved with some small tricks. For example, use bidirectional heartbeats to promptly exclude such “half-connected” servers.
Leader and Term
So how is it guaranteed that at most one Leader is elected in a given term?
- One must receive more than half of the votes from the cluster servers to become Leader.
- Each server can cast at most one vote in each term.
- If it is a Candidate, it votes for itself unconditionally.
- If it is not a Candidate, it votes for the first Candidate that asks for a vote (and meets certain conditions, which will be mentioned in the next section).
Moreover, when a network partition occurs, it is still guaranteed that there is at most one Leader; even if a small number of servers crash, a Leader can still be elected normally.
Leader Heartbeat
A Candidate becomes the Leader after obtaining a majority of votes, but at this point only the Leader itself knows it is the Leader, and other servers have no way of knowing. Therefore, heartbeats are needed to broadcast this election result to other servers. When a server receives a heartbeat, if it finds that the heartbeat’s term is greater than its own, it recognizes the sender as the Leader for that term, updates its own term to the Leader’s term, and then becomes a Follower.
After that, the Leader uses continuous heartbeats to suppress Followers from transitioning to Candidates, i.e., to suppress other servers from initiating elections. This also requires the Leader’s heartbeat interval to be smaller than the election timeout.
Split Vote
Within a given term, there are two situations that can prevent a Leader from being elected:
- No majority of servers can reach each other.
- Multiple Candidates initiate elections simultaneously, and none of them obtains a majority of votes.
To avoid an infinite loop where multiple Candidates continuously initiate elections simultaneously, time out simultaneously to enter the next term, and then initiate elections simultaneously again, Raft introduces randomness: each server’s election timeout is not a fixed value, but a random value within a certain range. Thus, after a collision in one election, because the election timeouts are chosen differently, the next election initiation will inevitably be staggered. Of course, merely staggering is not enough; they must be staggered by enough time to ensure that a certain Candidate starts asking for votes from other servers before they time out, thereby avoiding another election collision.
Election Timeout
So how should the election timeout be chosen?
- Its minimum value should ideally be greater than several times (more than two) the heartbeat interval; because the network occasionally drops packets, causing some heartbeats to be lost, which may trigger unnecessary elections.
- The random range should be as large as possible, so that the server that times out fastest can promptly initiate an election to other servers and become the Leader.
- But it cannot be too long, to prevent the system from stalling for a long time when it loses the Leader.
- In our lab, too long a timeout will cause tests to fail (the test program has time limits on the process of electing a Leader).
Old Leader
When a network partition occurs, the old Leader and a minority of servers are isolated into one partition, and the remaining majority of nodes will elect a new Leader. If the old Leader cannot感知 (be aware of) the emergence of the new Leader, what problems will arise?
- The old Leader will not commit any log entries, because it cannot get a majority of Followers to synchronize log entries.
- Although it will not commit, some servers will accept the old Leader’s log entries, causing log divergence among servers in the cluster.
Log Divergence
When everything is running normally, the situation is simple: Followers only need to unilaterally accept the log entries synchronized to them by the Leader. But when anomalies occur—for example, the Leader synchronizes log entries to only some of the machines and then crashes—how should the system proceed?
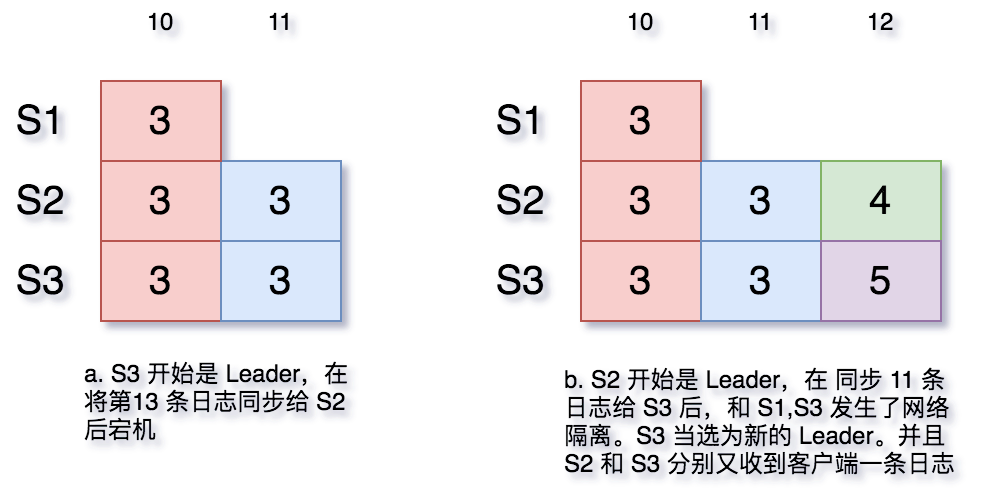 log-and-crash
log-and-crash
Of course, in figure a above, the 11th log entry may or may not have been committed by the old Leader. But if the new Leader has no way of knowing, it can only assume it was committed based on the majority vote principle (more than half of the servers have that log entry).
References
- English lecture notes
- Video

