 6.824-schedule.png
6.824-schedule.png
MIT has finally released the lecture videos on YouTube this year. I followed about half of this course before, and this year I plan to watch the videos and write some lecture notes. The course follows the thread of distributed systems fundamentals: fault tolerance, replication, and consistency, using carefully selected industry-grade system papers as the main line, supplemented with detailed reading materials and well-crafted labs, bridging academic theory and industrial practice. It is truly an excellent distributed systems course. Course videos: YouTube, Bilibili. Course materials: 6.824 homepage. This post is the notes for the fourth lecture, VM-FT.
Replication — Fault Tolerance
Failure
How to define it? From the perspective of other computers, it stops providing services externally.
Through backup / replication (Replication)
Can solve: fail-stop, such as CPU overheating shutdown, host or network power failure, disk space exhaustion, etc.
Cannot solve: some correlated issues (where the primary and replica machines fail simultaneously), such as software bugs, human configuration errors.
Prerequisite
One assumption for primary-backup replication to work is that the failure probabilities of the primary and backup machines need to be independent.
For example: machines from the same batch, or machines on the same rack, have strongly positively correlated failure probabilities.
Is It Worth It
It is necessary to consider the business scenario and the required cost to determine whether replication is truly needed. For example, bank data needs multiple backups, while a course website may not.
Author: Muniao’s Notes https://www.qtmuniao.com/2020/04/01/6-824-video-notes-4-vm-ft/, please indicate the source when reposting
Primary-Backup Paper
Two ways to perform state backup:
- State transfer
Continuously incrementally synchronize the Primary’s state to the Backup, including CPU, memory, I/O devices, etc.; however, these states usually consume a large amount of bandwidth, especially memory changes. - Replicated State Machine
Treat the server as a deterministic state machine; as long as the same initial state and the same sequence of deterministic inputs are given, the same state can be maintained. What is synchronized are external events / operations / inputs; the synchronized content is usually smaller, but it depends on some characteristics of the host: such as the determinism of instruction execution. Ensuring determinism on physical machines is difficult, but it is much simpler on a VM, because the hypervisor has complete control over the VM, so certain means can be used to additionally synchronize some non-deterministic inputs (such as random numbers, system clocks, etc.).
Generally, operations are much smaller than state, so Replicated State Machine is adopted.
Q&A:
- What happens if the primary and backup become inconsistent for some reason?
Consider the example in GFS where two chunkservers both believe they are the Primary due to network partition. - If there are instructions that depend on random numbers, how does Replicated State Machine synchronize them?
This is exactly the significance of the previously emphasized requirement for instruction determinism. Of course, when encountering such commands, the Backup can also directly accept the execution result from the Primary.
In addition, Replicated State Machine requires the machine to be single-core, because on multi-core machines, the execution order of instructions itself is non-deterministic. So how to synchronize on multi-core machines? State Transfer.
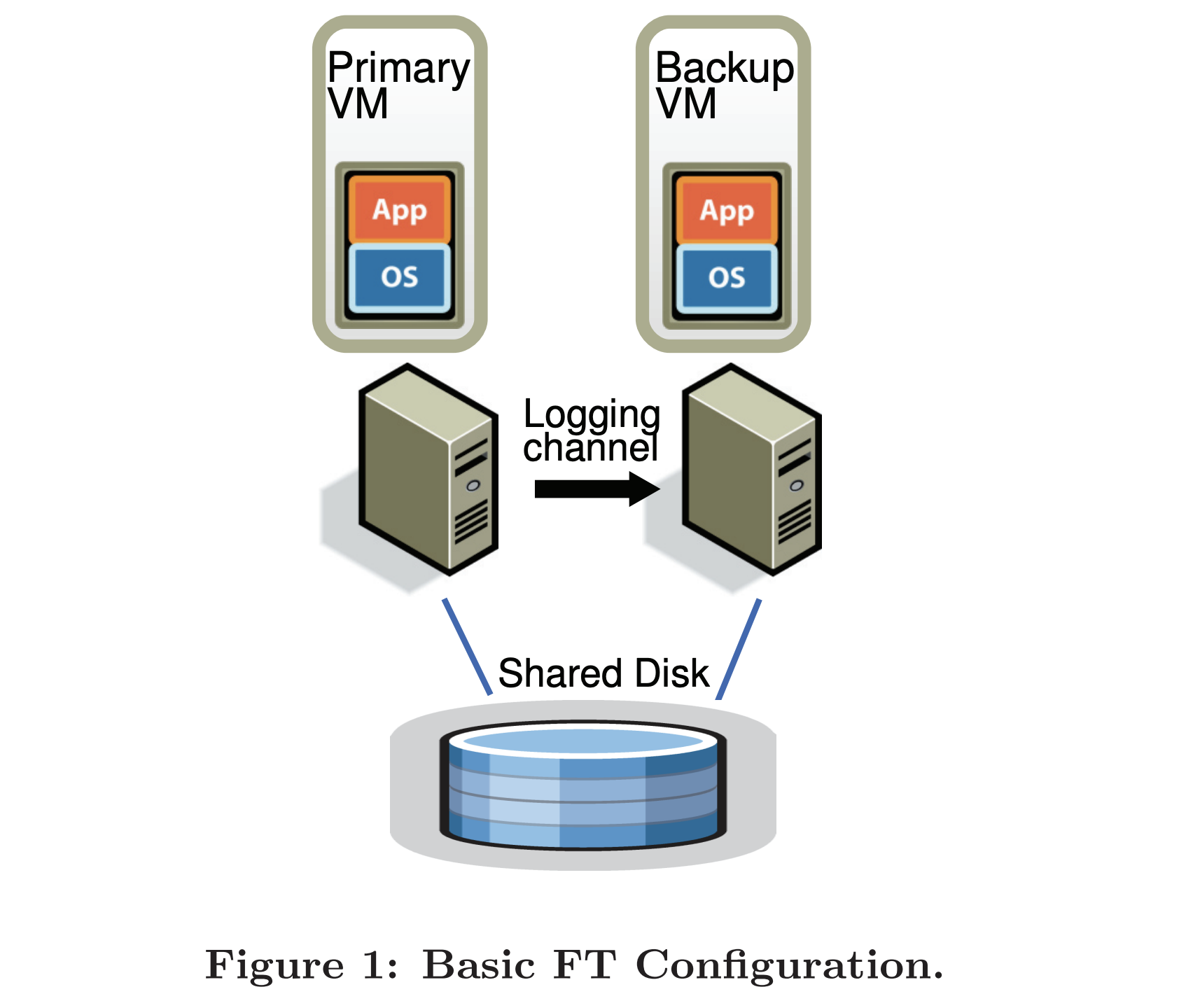 pb-ft-configuration.png
pb-ft-configuration.png
Challenges
- What state needs to be synchronized?
- Does the Primary need to wait for the Backup?
- How to perform failover when the Primary crashes?
- How to perform fast recovery when the Primary / Backup crashes.
Levels of state synchronization:
- Application state. Such as GFS, more efficient, only needs to send high-level operations; the disadvantage is that fault tolerance must be implemented at the application layer.
- Machine level. Can enable applications running on the server to obtain fault tolerance without modification. But it requires fine-grained synchronization of machine events (interrupts, DMA); and it requires modifying the underlying machine implementation to send these events.
VM-FT chose the latter, which is more powerful but also made more sacrifices.
The VM-FT system uses an additional virtualization layer, VMMonitor (hypervisor == monitor == VMM). When a client request reaches the Primary, the VMMonitor forwards the request to the local machine on one hand, and synchronizes the request to the Backup’s VMMonitor on the other. When the request is processed and a result is obtained, the Primary’s VMMonitor replies to the Client, while the Backup’s VMMonitor discards the reply produced by the Backup.
Two methods are used to detect the health of the Primary and Backup:
- Heartbeating with the Primary / Backup.
- Monitoring the logging channel.
Failover
How to achieve failover between primary and backup? After the Primary crashes, the Backup claims to have the Primary’s MAC address, and then lets the ARP cache expire, diverting traffic destined for a certain IP from the Primary to the Backup.
After the switch, the original Backup becomes the new Primary and replies externally. Then, using VMotion technology, a replica is started on shared external storage with the new Primary, and a logging channel is established.
Non-Deterministic Events
What are the non-deterministic operations and events?
- Input non-determinism. System interrupt events.
- Strange instructions. Such as random numbers, instructions dependent on timestamps.
- Multi-core. Different machines may interleave instruction execution on multi-core in different ways.
For non-deterministic operations, sufficient information needs to be retained in the logging channel so that the Backup can make the same state changes and produce the same output. For non-deterministic events, such as clock signal interrupts and I/O completion interrupts, not only the event itself needs to be recorded, but also the position in the instruction sequence where the event occurred, so that it can be deterministically reproduced on the Backup.
Logging Channel
To achieve Fault Tolerance (FT), we use log entries to record events occurring on the Primary; but we do not write these logs to disk, instead transmitting them to the Backup through the logging channel for real-time deterministic replay. Each LogEntry may contain the following data:
- Instruction number
- Instruction type
- Data
DMA
DMA can directly copy data from the network port to memory without going through the CPU. At this time, the VMM needs to forcibly interrupt, copy the incoming data, simulate an instruction, and send it to the Backup.
Output Rule
When the Primary crashes, the last instruction it sent to the Backup is also lost due to network issues. When the Backup takes over, how to handle the inconsistency caused by the loss of this instruction?
It is guaranteed by the Output Rule. That is, the Primary only sends the instruction result to the user when it receives an ACK from the Backup for that instruction. Of course, to reduce response latency, on the Backup side, the VMM only needs to buffer the received instruction in a Buffer before sending back the ACK. Moreover, the Primary only delays sending the reply to the user to wait for the Backup’s ACK, but does not really stop executing during this waiting time, after all, network request replies are asynchronous, and the Primary can do other things in parallel.
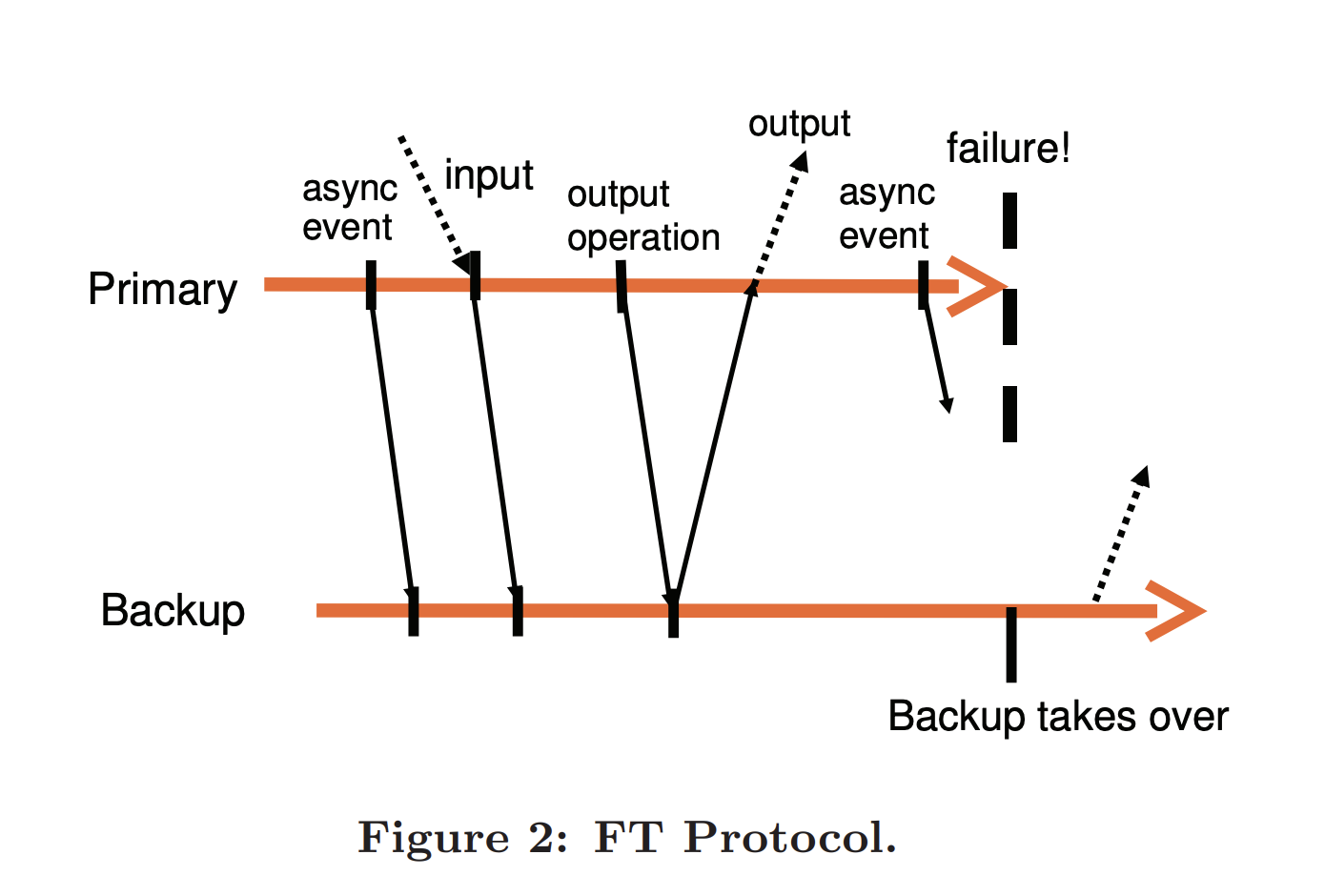 pb-ft-protocol.png
pb-ft-protocol.png
After the Primary crashes and the Backup takes over, duplicate results may be produced. However, because P/B share a TCP channel, the SEQ number will also be reused, and will be ignored as a duplicate TCP frame on the Client side, thus not being exposed to the user level.
Throughput
If the Primary and Backup are not in the same city, and each communication takes several milliseconds, it is difficult to build a high-throughput system.
Network Partition
If the network between P/B is broken, but both can still communicate with the client, split-brain occurs. The solution is to introduce a third-party arbiter to keep track of who is allowed to respond: for example, using a TAS (Test-and-Set Server) or shared external storage.

