Overview
Bw-tree is a data structure proposed in a paper published by Microsoft in 2013. Considering the increasing prevalence of multi-core machines and SSDs, and combining the characteristics of the two major storage engines B±tree and LSM-tree, it proposes a latch-free, delta-update, log-structured B-tree family — Bw-tree.
Since the original paper is vague on implementation details, several authors from CMU implemented an in-memory version of Bw-tree in 2015, and then published another paper to supplement some implementation details, open-sourcing the code on GitHub as open bwtree.
As usual, here is a summary (TL;DR). The main characteristics of Bw-tree are:
- Overall three layers: Bw-tree index layer, cache control layer, and Flash storage layer.
- Bw-tree is globally a B+ tree, while borrowing ideas from the B-link tree: each node has a side pointer to its right sibling.
- At the individual tree node level, Bw-tree resembles an LSM-tree-like log structure: each logical node consists of a base node + a delta records chain.
- The core data structure enabling latch-free operation in Bw-tree is called the Mapping Table. Installing is done via CAS; modifying a mapping entry can simultaneously update multiple logical pointers.
- The Bw-tree flash layer also uses a Log-Structure Store (append-only) to manage the physical storage of logical pages (base pages and delta records).
Author: Woodbird Miscellany https://www.qtmuniao.com/2021/10/17/bwtree-index, please indicate the source when republishing
Motivation
New data structures are often designed to adapt to changes in hardware. So what trends have there been in hardware in recent years? On the one hand, after single-core performance has been pushed to the limit (Moore’s Law has faltered), multi-core architectures have become a major development direction. However, traditional lock-based concurrent data structures struggle to fully exploit multi-core performance, because excessive locking leads to frequent waiting and context switching. On the other hand, flash memory has become increasingly cheap and is gradually becoming the primary storage medium. But flash has unique read/write characteristics: sequential writes are several times faster than random writes, and random read concurrency is far superior to traditional disks.
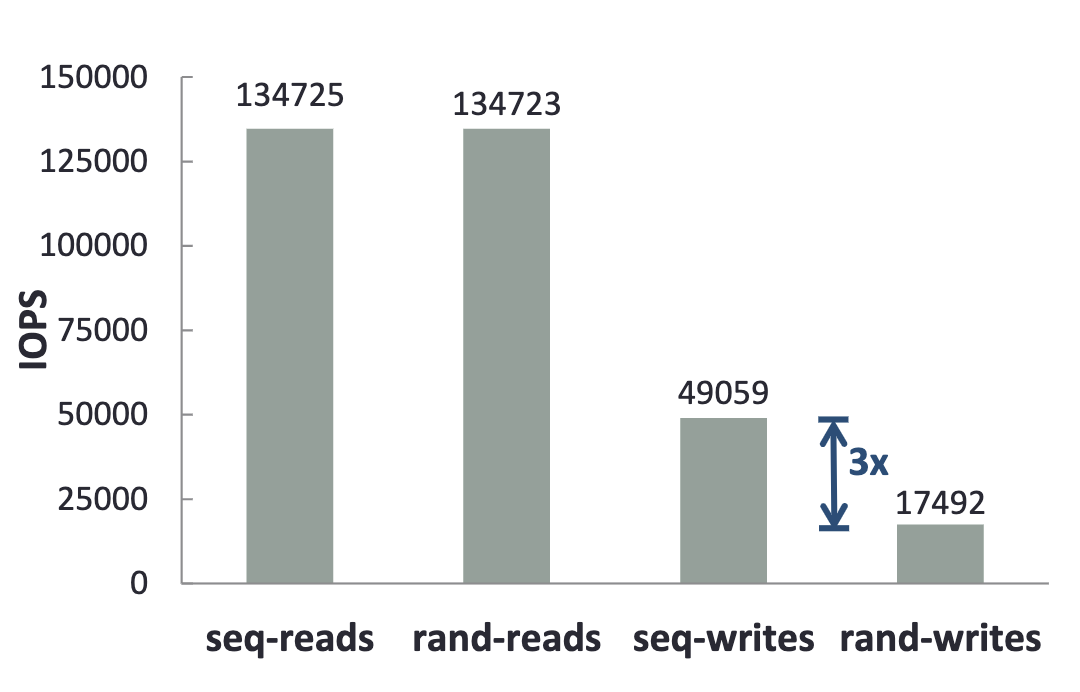 Flash read/write performance comparison
Flash read/write performance comparison
In response to these two observations, Microsoft designed Bw-tree. Bw-tree uses latch-free structures for incremental updates in memory:
- Latch-free structures reduce context switching and improve parallel throughput.
- Incremental updates avoid cache misses caused by in-place updates.
It uses a Log-Structure Store to manage physical data storage on external storage:
- Append-only writes can fully exploit flash’s characteristics of fast sequential write speed and high throughput.
- Although this may introduce more random reads, flash happens to offer higher random read concurrency.
Architecture
The architecture diagram of Bw-tree is as follows:
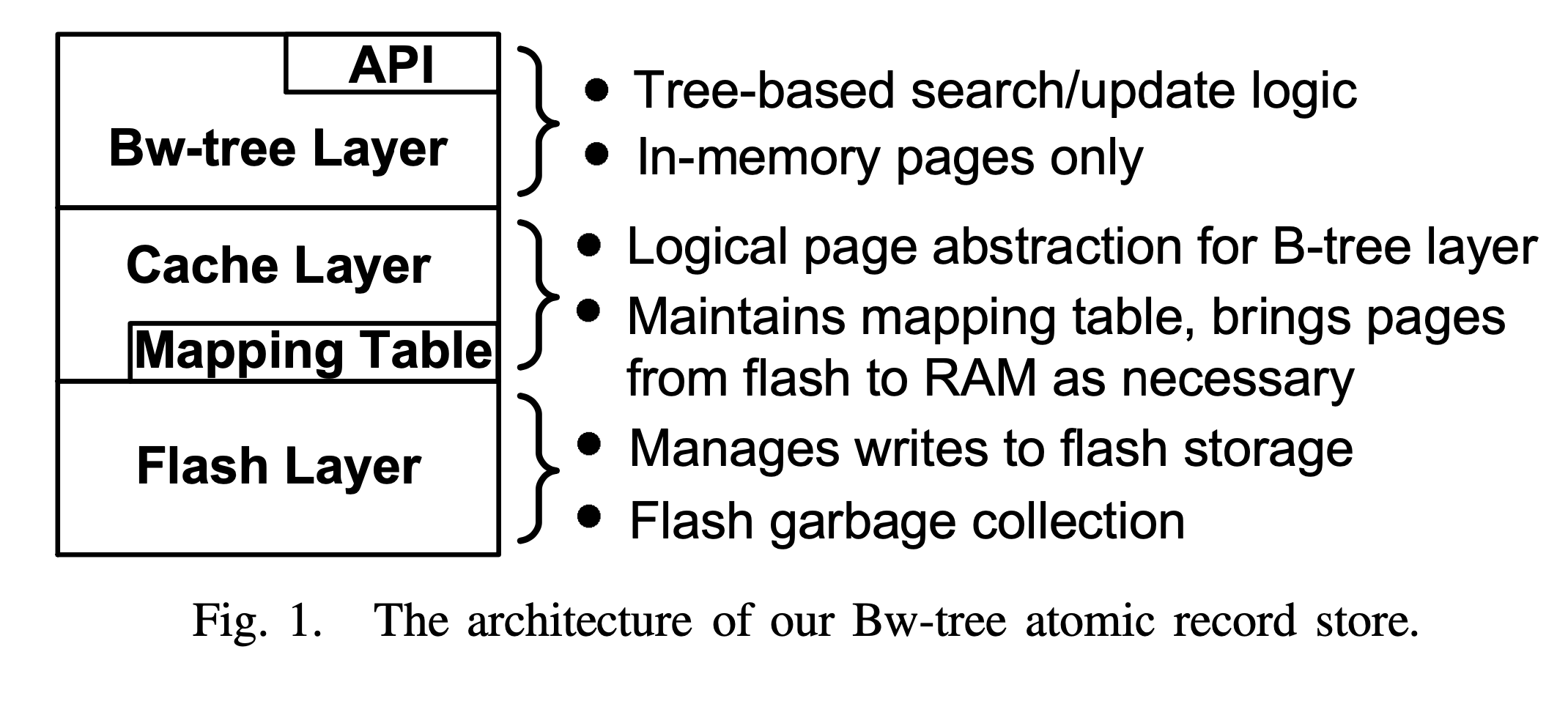 Bw-tree architecture diagram
Bw-tree architecture diagram
Bw-tree is divided into three layers overall: the logical Bw-tree index layer, the physical Log Structured Store storage layer, and the intermediate cache layer that bridges the two. The cache layer uses a core data structure — the Mapping Table — to record the mapping from Page ID to physical pointer and to control data movement between memory and flash.
Bw-tree Index
Bw-tree provides record (key-value) level interfaces externally. The overall structure is shown below.
Bw-tree nodes are elastically variable, consisting of a base node and a delta records chain. All modifications to a node, including insert, modify, and delete, are appended to the head of the chain as delta records.
Bw-tree pointers include two types: physical pointers (physical links) within nodes and logical pointers (logical links) between nodes. Logical pointers are page IDs and need to be used together with the Mapping Table, because the latter records the mapping from page ID to physical pointer. Physical pointers are represented as pointers in memory, and as addresses on the file system or block storage on flash. Bw-tree nodes, if in memory, are linked together via memory pointers; if flushed to flash, they are chained together via physical addresses. The logical pointers between Bw-tree nodes, i.e., page IDs, are the key to concurrency control via CAS, and the reason will be explained in detail later.
Note: The term “Delta node” in the figure below is not very scientific; “Delta record” is more reasonable, because the granularity of information it stores is finer than a node — usually at the single record level.
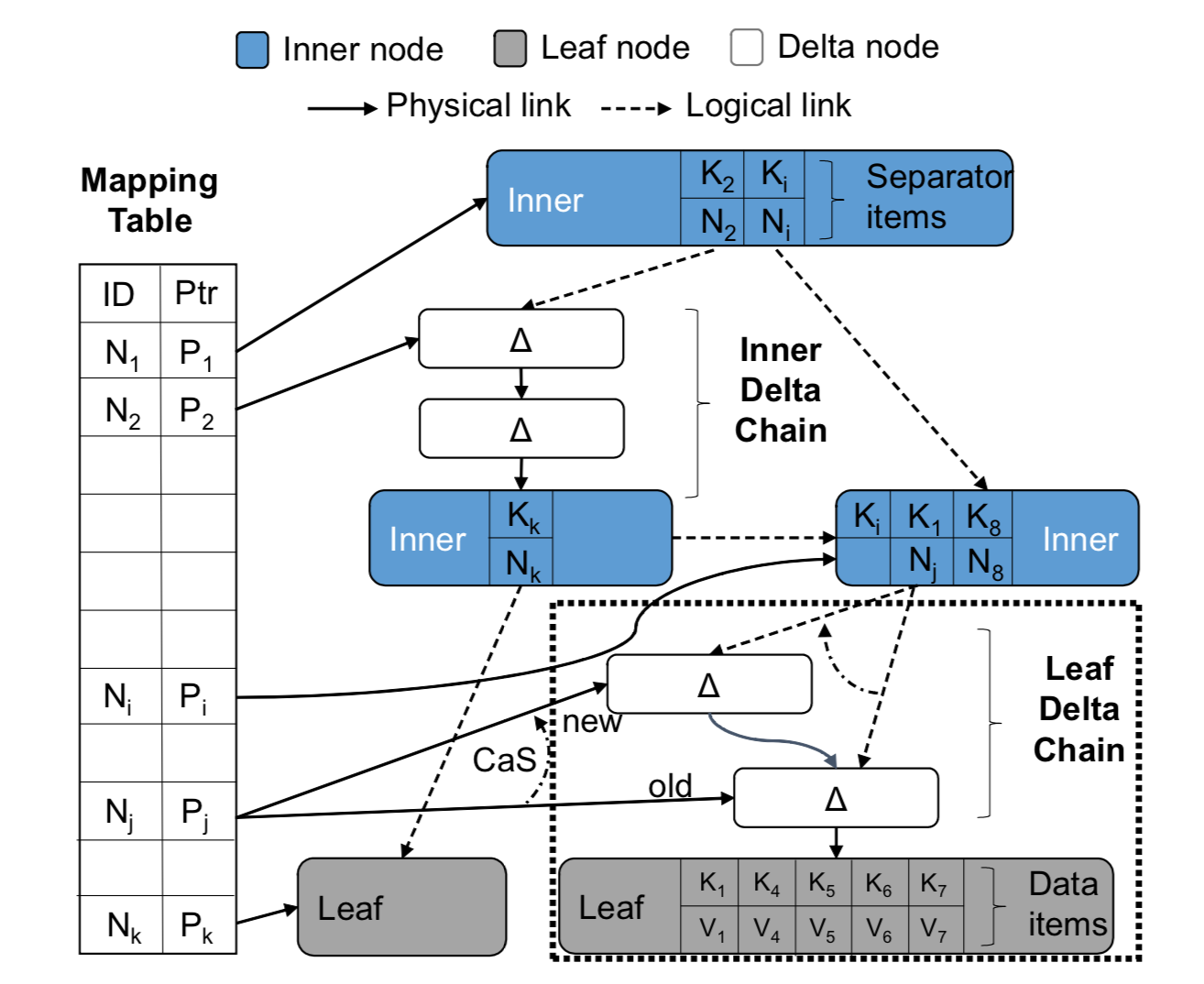 Bw-tree index schematic from CMU paper
Bw-tree index schematic from CMU paper
Delta record is a very important data structure in Bw-tree. There are mainly two types: one is key-value incremental modifications for leaf nodes; the other is tree structure modifications for inner nodes. Delta records contain several important fields: low Key, high Key, and side pointer.
Let us consider from the designer’s perspective: what information should a delta record contain? A simple list:
- It should contain necessary incremental information (key-value pairs) so that it can be applied to the original node.
- It should contain some redundant information (low key, high key) to optimize lookups.
- It should contain some pointers (borrowing the side pointer from B-link) so that concurrent scans are not affected during tree structure adjustments.
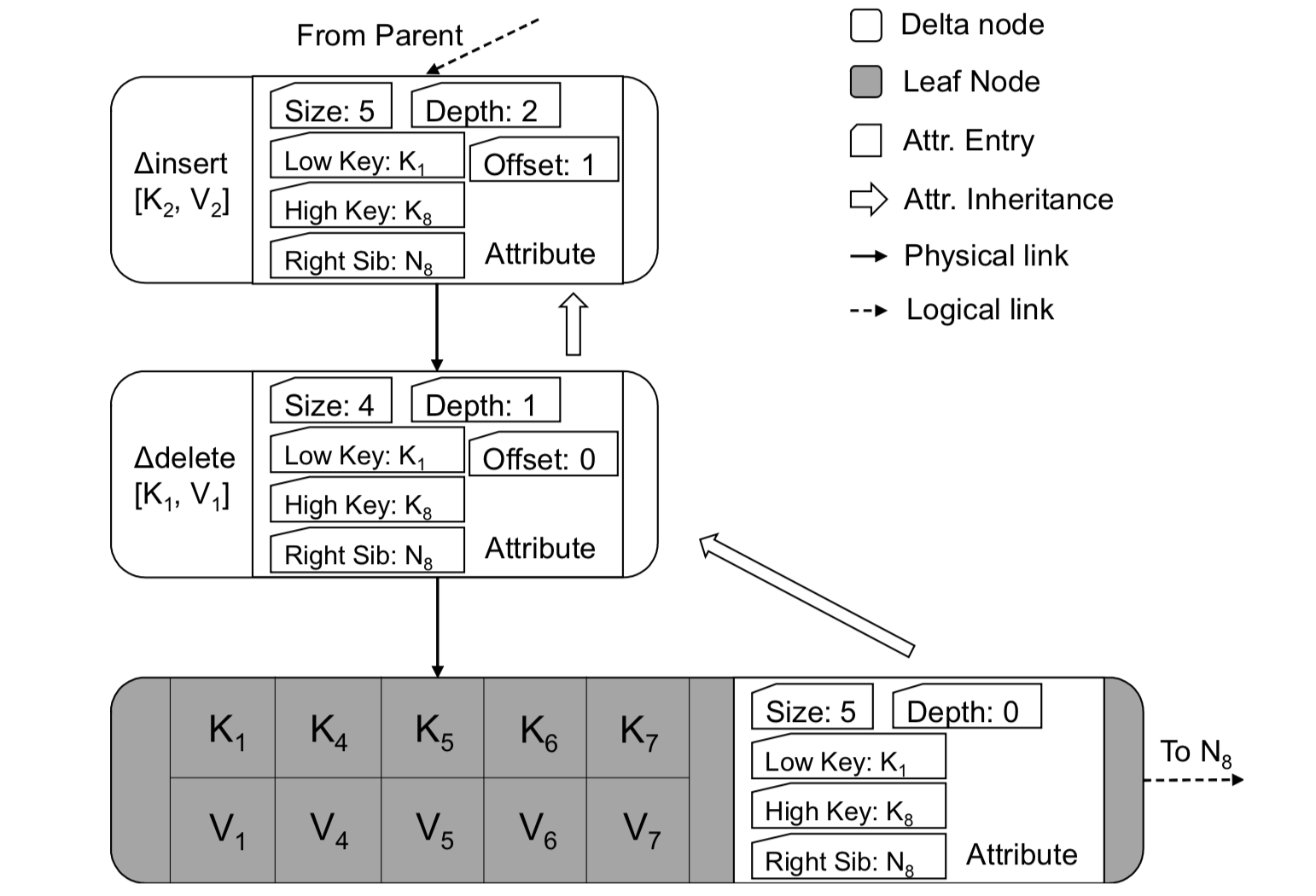 Bw-tree logical node
Bw-tree logical node
Next, let us walk through the above design with some typical scenarios. Common scenarios include: modifications to a single node (appending delta records containing key-value pairs), usually for leaf nodes; and large-scale modifications to the tree structure, usually caused by splitting or merging subtrees due to too many insertions or deletions, involving both leaf nodes and inner nodes.
Single-Node Operations
Single-node operations mainly include updates (insert, delete, modify), queries (point query, range query), and consolidation. Among them, update operations are all accomplished by introducing delta records. Point queries traverse the delta chain from the head until reaching the base node. Range queries prepare a key-value vector corresponding to the node in advance. Consolidation is essentially intra-node compaction.
Single-node changes generally only occur on leaf nodes, and their types are all modification operations on a single record (a key-value pair), including insert, delete, and modify. Bw-tree turns these modifications into a delta record, appends it to the modification chain within the node, and then updates the chain head pointer in the mapping table to complete the modification.
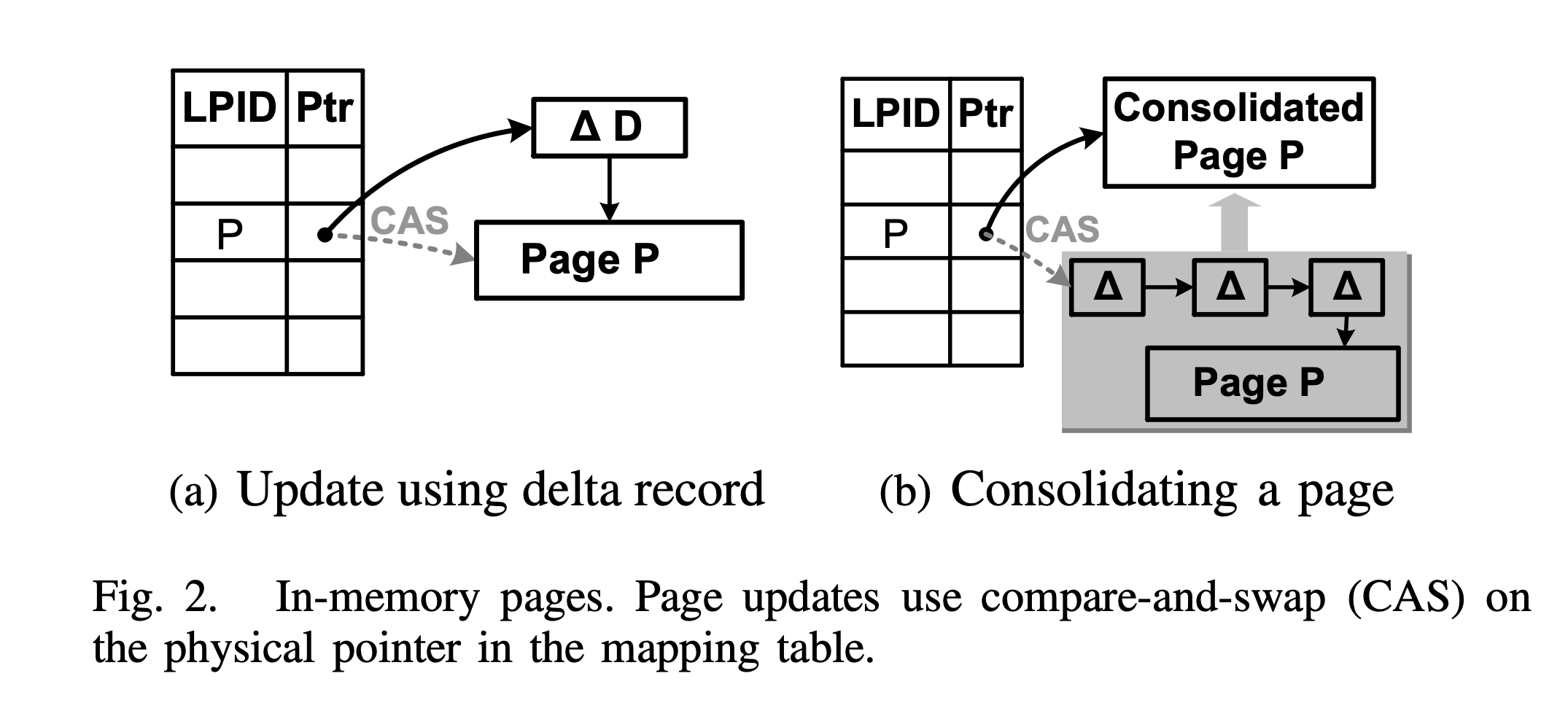 Bw-tree single-node operations
Bw-tree single-node operations
As shown in Figure a, the steps for incrementally modifying Page P are as follows:
- Allocate a new delta record in memory (denoted as △D in the figure).
- Assign values to it, including incremental information (such as modification type, key-value pair to be modified), lookup optimization information (such as low key, high key), and a physical pointer to the current delta chain.
- Through a CAS operation, modify the corresponding entry in the Mapping Table to install it, making it point to the new head of the delta chain.
For a single node, in order to free up space, a consolidation operation is also performed, as shown in Figure b. The steps are as follows:
- Allocate a new page in memory.
- Merge the delta records and the base page, and copy them into the newly allocated page.
- Through a CAS operation, modify the corresponding entry in the Mapping Table to install it.
The consolidation operation is somewhat similar to compaction in LSM-tree, except with finer granularity.
Tree Structure Modifications
Tree structure modifications, referred to as SMO (index structure modification operation) in the Microsoft paper, include split and merge. Since a single tree structure adjustment is difficult to complete with a single CAS operation, Bw-tree decomposes it into multiple steps. However, to ensure that nodes remain externally visible during the intermediate states of the adjustment, Bw-tree borrows ideas from the B-link tree:
- Each node maintains a right pointer (side pointer) pointing to its right sibling node.
- Each split is only allowed to split to the right.
The purpose is that even if the index of the newly split node has not been added to the parent node, it can still be accessed via the right pointer of the predecessor node.
That is, although the child node has split, the connection remains, and the nodes are still chained together via pointers.
In addition, unlike key-value modification deltas for leaf nodes, inner node modification deltas are special deltas, which will be introduced in detail below.
Tree structure modifications include node split and node merge.
Node Split.
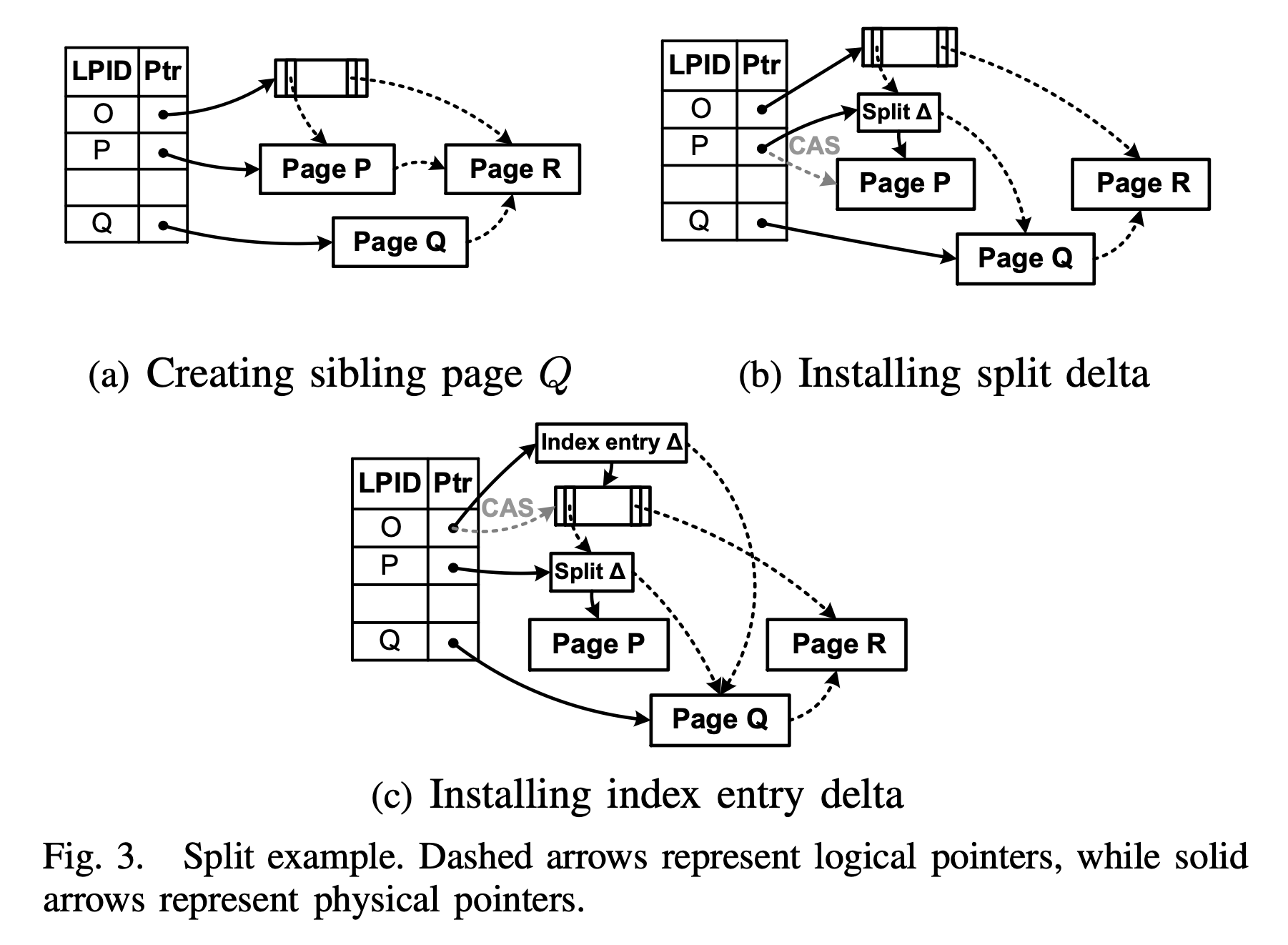 Bw-tree node split process
Bw-tree node split process Untitled
Untitled
As shown in the figure, splitting Page P is divided into two phases: child split (corresponding to Figures a and b), and parent update (corresponding to Figure c). Each phase uses a CAS operation to make the modification externally visible:
- Create Page Q to hold the right half of the key-value pairs of Page P, and logically set its side pointer to Page R, the right sibling of Page P. At this point, Page Q is not externally visible, i.e., it is unreachable from the Bw-tree root.
- Install the split delta. In order to make Page Q externally visible, Bw-tree introduces a special delta record: the split delta. This split delta contains the split key from the original Page P, which is used to route lookups between Page P and Q; it also records Page Q as its side pointer. Finally, through a CAS operation, the split delta is installed into the mapping table.
- Install the index entry delta. After Page Q splits from Page P, an index entry needs to be added to the parent node pointing to the new node Page Q. Bw-tree accomplishes this by introducing an index entry delta. In addition to containing SplitKey-PQ and Pointer-PQ, the index entry delta also contains a SplitKey-QR, so that queries falling in
[SplitKey-PQ, SplitKey-QR)can be routed directly to Page Q.
Although the various pointers in the figure look dazzling, understanding them only requires grasping a few characteristics:
- Solid lines are real physical pointers; dashed lines are logical pointers, i.e., Page IDs.
- Physical pointers within a node are completed when the delta record is created; physical pointers in the Mapping Table are updated via CAS operations.
- After updating the record in the Mapping Table, the dashed pointers in the figure change their direction accordingly.
Node Merge.
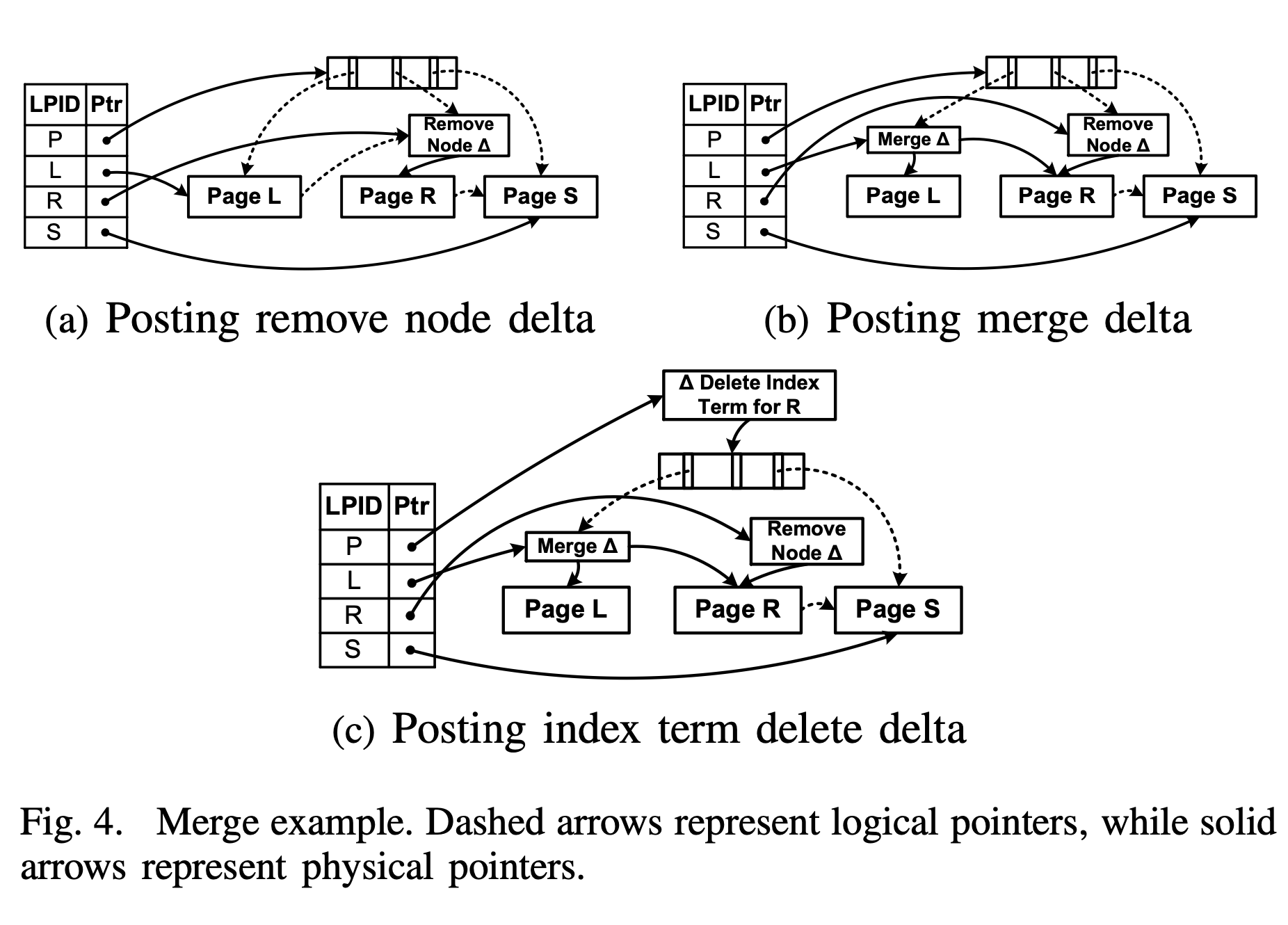 Bw-tree node merge process
Bw-tree node merge process
As shown in the figure, merging Page R into Page L is divided into three phases, each containing a CAS operation:
- Marking for Delete: Introduce a Remove Node Delta, append it to Page R, and then update the value corresponding to Page R in the mapping table via a CAS operation, marking Page R as deleted. However, at this time, Page R can still be accessed via Page L’s side pointer, i.e., the remove node delta only blocks access from the parent node.
- Merging Children: Introduce a Node Merge Delta (following the name in the paper, but the naming is asymmetrical with Remove Node Delta; not sure if there is any special consideration). This delta records the physical pointers to Page L and Page R, and then updates the value of Page L in the mapping table via a CAS operation, i.e., this delta is logically part of page L.
- Parent Update: Introduce an Index Term Delete Delta, append it to the parent node, logically deleting the key and pointer previously pointing to Page R, and then update the value of the parent node P in the mapping table via a CAS operation.
From Figure a, it can be seen that when updating the value of Page R in the mapping table to install the Remove Node Delta, two logical pointers are simultaneously modified:
- Page L’s side pointer pointing to Page R.
- Parent node Page P’s child pointer pointing to Page R.
This is also the significance of the mapping table and logical pointers: by CAS-modifying a single mapping table entry, the goal of simultaneously modifying multiple logical pointers is achieved.
Handling Conflicts
If one node is undergoing an SMO operation while another thread wants to perform a single-node update, but a conflict occurs with the SMO operation (e.g., operating on the same Page), how should the conflict be resolved?
Generally, Bw-tree is embedded as a storage engine into a DBMS, and the transaction management module in the DBMS will try to handle external conflicts and serialize multiple SMO operations (personal guess). Then Bw-tree handles conflicts between SMO operations and single-node updates.
Bw-tree adopts a scheme called “the help-along protocol”, meaning that any thread, upon discovering an ongoing SMO operation, will first execute the SMO operation and then execute its own operation (insert, delete, modify, query). That is:
- The priority of SMO is raised to determine the ordering between the two types of updates (SMO and single-node updates).
- All threads, when encountering a conflicting SMO, regardless of whether it belongs to their own operation, will first complete the SMO. This way, some thread will always complete the SMO and be able to continue, while other threads simply abandon it.
Cache Management
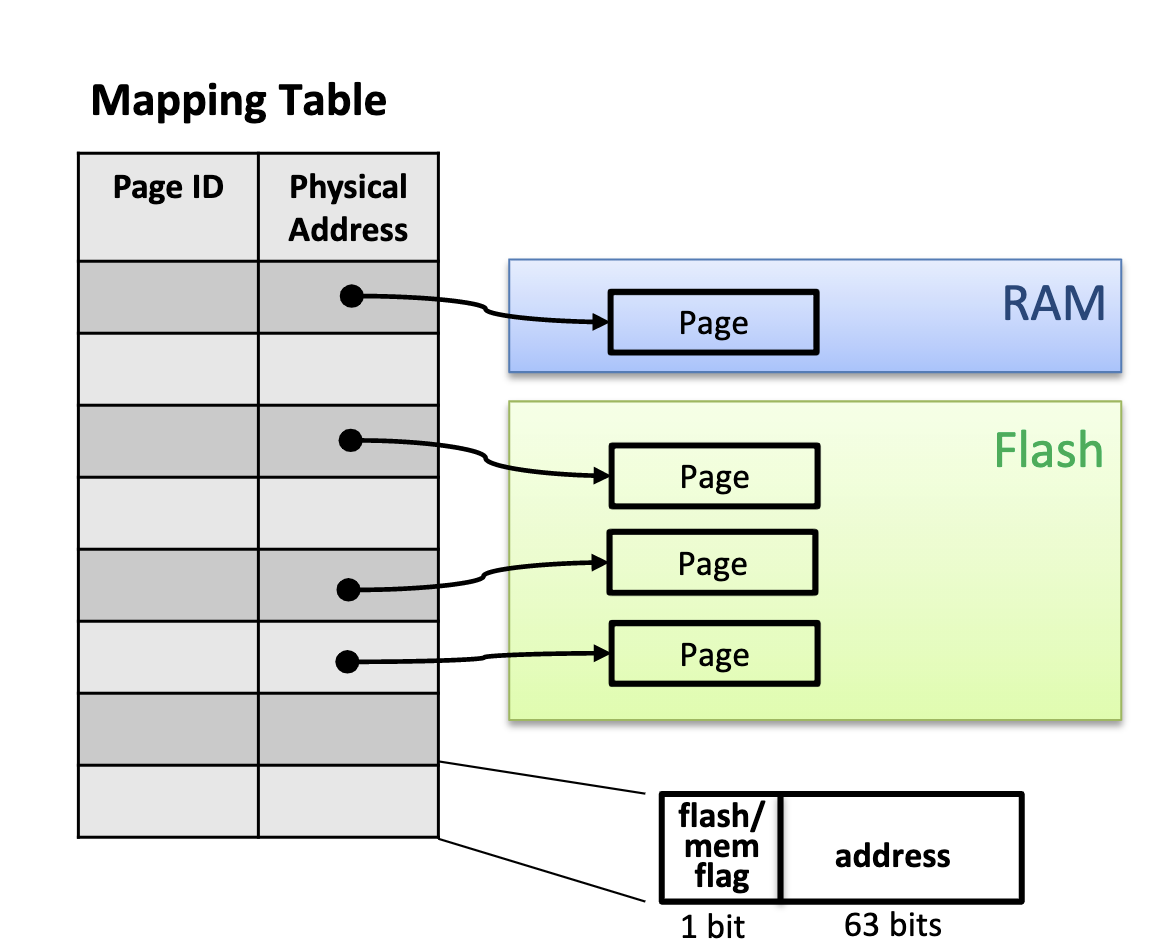 Bw-tree mapping table
Bw-tree mapping table
Main Functions
The main functions of the cache layer are:
- Maintain the Mapping Table, storing the mapping from logical PID to physical address. The physical address may be a pointer in memory, or an address in the flash file system.
- Be responsible for moving pages between memory and flash, including reading, swapping, and flushing.
Mapping Table Updates
All updates to the mapping table are completed via latch-free CAS, including:
- Physical pointer changes caused by appending delta records to leaf nodes and inner nodes.
- Replacement of memory pointers and file addresses caused by swapping pages between flash and memory.
Incremental Flushing
There are many reasons that can cause pages in the cache to be flushed, such as checkpointing requested by upper-layer transactions, or memory usage reaching a threshold requiring eviction. As mentioned earlier, a logical page consists of a base page and a delta chain, and the delta chain will continue to grow within a threshold range. Therefore, flushing a logical page is not done all at once, but also incrementally. For this purpose, Bw-tree introduces another special flush delta, recording the flush point and adding it to the logical page. This way, if there are modifications, only the delta records after the flush point need to be flushed next time.
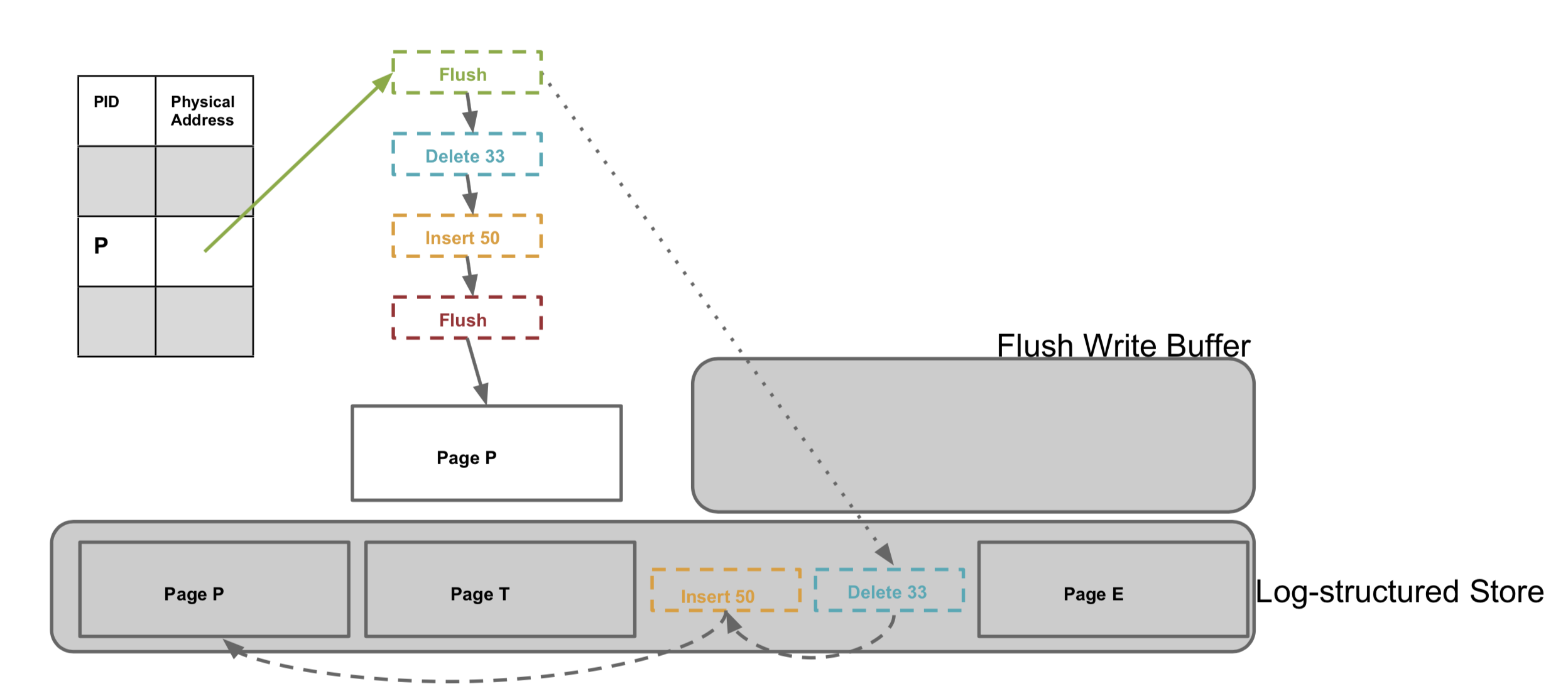 Bw-tree storage structure and incremental flushing
Bw-tree storage structure and incremental flushing
Flash Layer (Log-Structured Store, LSS)
The flash layer corresponds to memory; both flush data incrementally to disk. Data for a single logical page is not contiguous; within a page, data is chained together via file system addresses.
Garbage collection is performed using rewriting, during which multiple parts of a logical page can be moved together to reduce subsequent read amplification.
Further Reading
Reading Microsoft’s Bw-tree paper alone, the storage and transaction parts are not easy to understand, because this paper only describes the Bw-tree index part in detail. As for the storage and transaction parts, one must look at two other papers from Microsoft, like a Russian nesting doll. I will publish two more related articles when I have the opportunity:
- Cache layer and flash layer: LLAMA: A Cache/Storage Subsystem for Modern Hardware, http://www.vldb.org/pvldb/vol6/p877-levandoski.pdf
- Transaction-related: Deuteronomy: Transaction Support for Cloud Data, https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/Deut-TC.pdf
References
- Microsoft 2013 Bw-tree paper: https://15721.courses.cs.cmu.edu/spring2017/papers/08-oltpindexes2/bwtree-icde2013.pdf
- Taobao Database Kernel Monthly Report 2018/11: http://mysql.taobao.org/monthly/2018/11/01

