Computation pushdown is actually a common idea: push computation to where the data resides. In databases, logically, computation usually sits above the storage layer, so pushing some operators down to the storage layer is called computation pushdown. This is especially important in distributed databases.
Below are the solutions from CockroachDB and TiDB, based on documentation and blog posts, so they may not be consistent with the logic in the latest code.
CockroachDB
Basic Concepts
The corresponding module in CockroachDB is called DistSQL, whose idea originates from Sawzall, somewhat similar to MapReduce. The supported operators are called aggregators, which are essentially a generalization of SQL aggregation operators.
Author: Muniqiao (Woodpecker’s Miscellany) https://www.qtmuniao.com/2022/04/05/crdb-tidb-dist-sql Please cite the source when reposting
Logically, each aggregator accepts an input stream of rows (Join will have multiple) and produces an output stream of rows (output stream of rows). A row is a tuple composed of multiple column values (column values). The input and output streams contain type information for each column value, i.e., the Schema.
CockroachDB also introduces the concept of groups (group), where each group is a unit of parallelism. The basis for dividing groups is the group key, which shows an idea somewhat similar to the Key in the Reduce phase of MapReduce. The group key is essentially a generalization of SQL’s GROUP BY. Two extreme cases:
- All rows belong to the same group. Then all rows can only be executed on a single node and cannot be parallelized.
- Each row belongs to a different group. Then the set of rows can be arbitrarily split for parallel execution.
aggregators
Some aggregators have special characteristics in their input, output, or logic:
- table reader has no input stream and directly fetches data from the local KV layer.
- final has no output stream and provides the final result to the query/statement.
- final and limit have ordering requirements (ordering requirement) on the input stream.
- evaluator can customize its behavior logic through code.
Logical to Physical
The execution process is somewhat similar to the topological scheduling and execution of DAGs in Spark.
- Reads are dispatched to each range, handled by the range’s Raft leader.
- When encountering a non-shuffle aggregator, it is executed concurrently on each node.
- When encountering a shuffle aggregator (such as group by), a certain hash strategy is used to send the output data to the corresponding machine.
- Finally, the final aggregator is executed on the gateway machine.
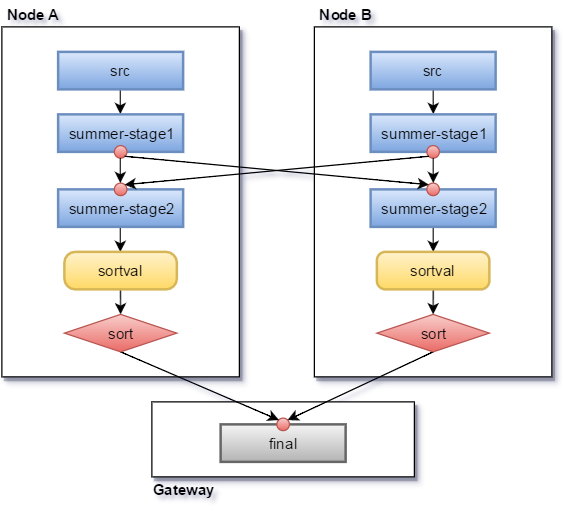 multi-aggregator.png
multi-aggregator.png
Single Processor
Each logical aggregator corresponds to a Processor physically and can be divided into three steps:
- Accept multiple input streams and merge them.
- Data processing.
- Distribute the output to different machines according to group.
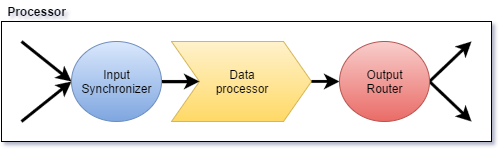 single-aggregator.png
single-aggregator.png
References
- cockroachdb SQL layer query execution: https://www.cockroachlabs.com/docs/stable/architecture/sql-layer.html#query-execution
- https://github.com/cockroachdb/cockroach/blob/master/docs/tech-notes/life_of_a_query.md
- cockroach db rfc 20160421_distributed_sql: https://github.com/cockroachdb/cockroach/blob/master/docs/RFCS/20160421_distributed_sql.md
TiDB
Basic Concepts
The main process of SQL execution in TiDB is:
- Perform lexical analysis to generate AST (Parsing)
- Use AST for various validations and transformations to generate a logical plan (Planning)
- Apply rule-based optimization to the logical plan to generate a physical plan (Optimizing)
- Apply cost-based optimization to the physical plan to generate an executor (Executor)
- Run the executor (Executing)
Since TiDB’s data is in the storage layer TiKV, in step 5, if all TiKV data involved is brought to the TiDB layer for execution, there will be the following problems:
- Excessive network overhead from the storage layer (TiKV) to the computation layer (TiDB).
- Excessive data computation in the computation layer consuming CPU.
To solve this problem and make full use of the distributed characteristics of the TiKV layer, PingCAP added a Coprocessor in the TiKV layer, which is a module that performs computation after reading data from the TiKV layer. When executing SQL (mainly reads), part of the physical plan (i.e., a DAG composed of some operators) is pushed down entirely to the TiKV layer, where the Coprocessor executes it.
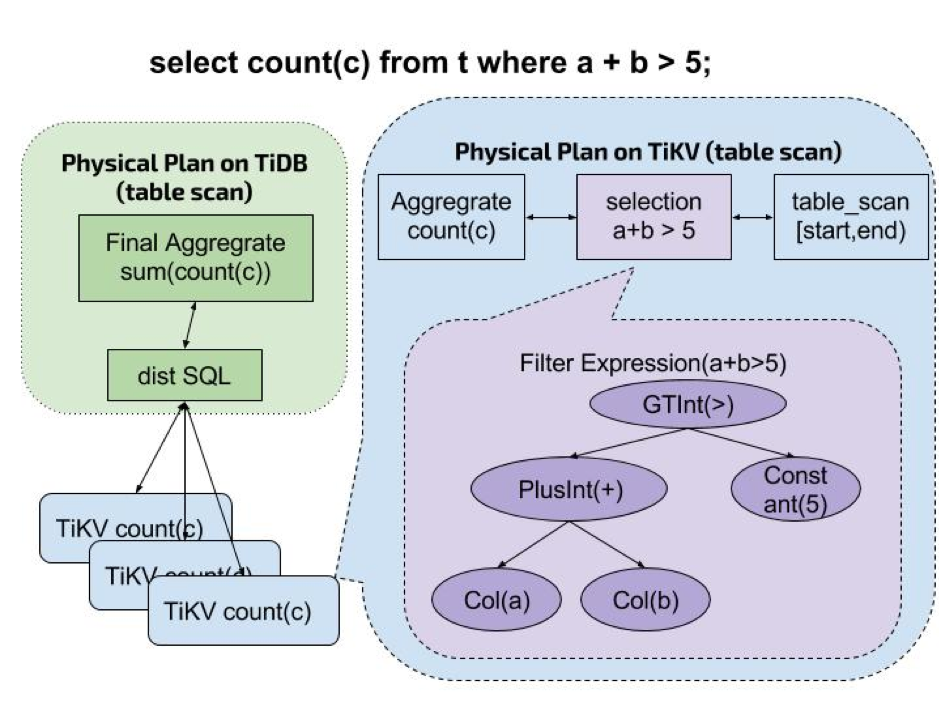 coprocessor.png
coprocessor.png
Executors
From the TiKV protobuf interface definition, it can be seen that the current TiKV-supported Coprocessor operators (also called Executors in TiKV) types are:
1 | enum ExecType { |
Single Coprocessor
Coprocessor accepts a DAGRequest composed of Executors as nodes, using the vectorized model:
- Scan specified data
- Execute all operators sequentially in units of Chunks
- Return results to the TiDB layer
Summary
The biggest difference between CRDB and TiDB when executing SQL is:
- CRDB uses an MPP model similar to MapReduce, so multiple storage nodes need to communicate and transfer data with each other.
- In TiDB, storage and computation are separated. Computations that can be pushed down are pushed down as much as possible in the form of a DAG, while computations requiring merging across multiple nodes can only be done at the computation layer. Therefore, multiple storage nodes do not need to communicate to transfer data.
This is a superficial understanding; if there are any inaccuracies or anything that needs to be added, please feel free to leave a comment.

