Source: https://engineering.fb.com/2022/05/04/data-infrastructure/delta/
TL;DR: I came across a new post on the Meta Engineering Blog about a highly available, strongly consistent, chain-replicated object storage system shared by someone in a group chat. Having worked on object storage myself and previously written about Facebook’s small-file storage systems — Haystack (batching) and F4 (hot/cold separation, erasure coding) — I was immediately intrigued to see what new insights Meta had to offer this time.
After reading it, I found it quite interesting. Below is a brief summary of the key points; interested readers can check out the original blog post and a related video featuring a Chinese engineer’s explanation.
What is Delta?
Delta is a simple, reliable, scalable, and low-dependency object storage system that provides only four basic operations: put, get, delete, and list. In its architectural design, Delta trades off read/write latency and storage efficiency for simplicity and reliability.
Delta is not:
- A general-purpose storage system. Delta only aims for elasticity, reliability, and minimal dependencies.
- A file system. Delta is simply an object store and does not provide POSIX semantics.
- A system optimized for storage efficiency. Delta does not optimize for storage efficiency, latency, or throughput; instead, it focuses on simplicity and elasticity.
Author: QtMuniao Notes https://www.qtmuniao.com/2022/05/06/meta-object-store-delta Please indicate the source when reposting.
In summary, its positioning is that of a foundational storage service: performance may not be top-tier, but it must be simple, elastic, and reliable. Its positioning is shown in the figure below:
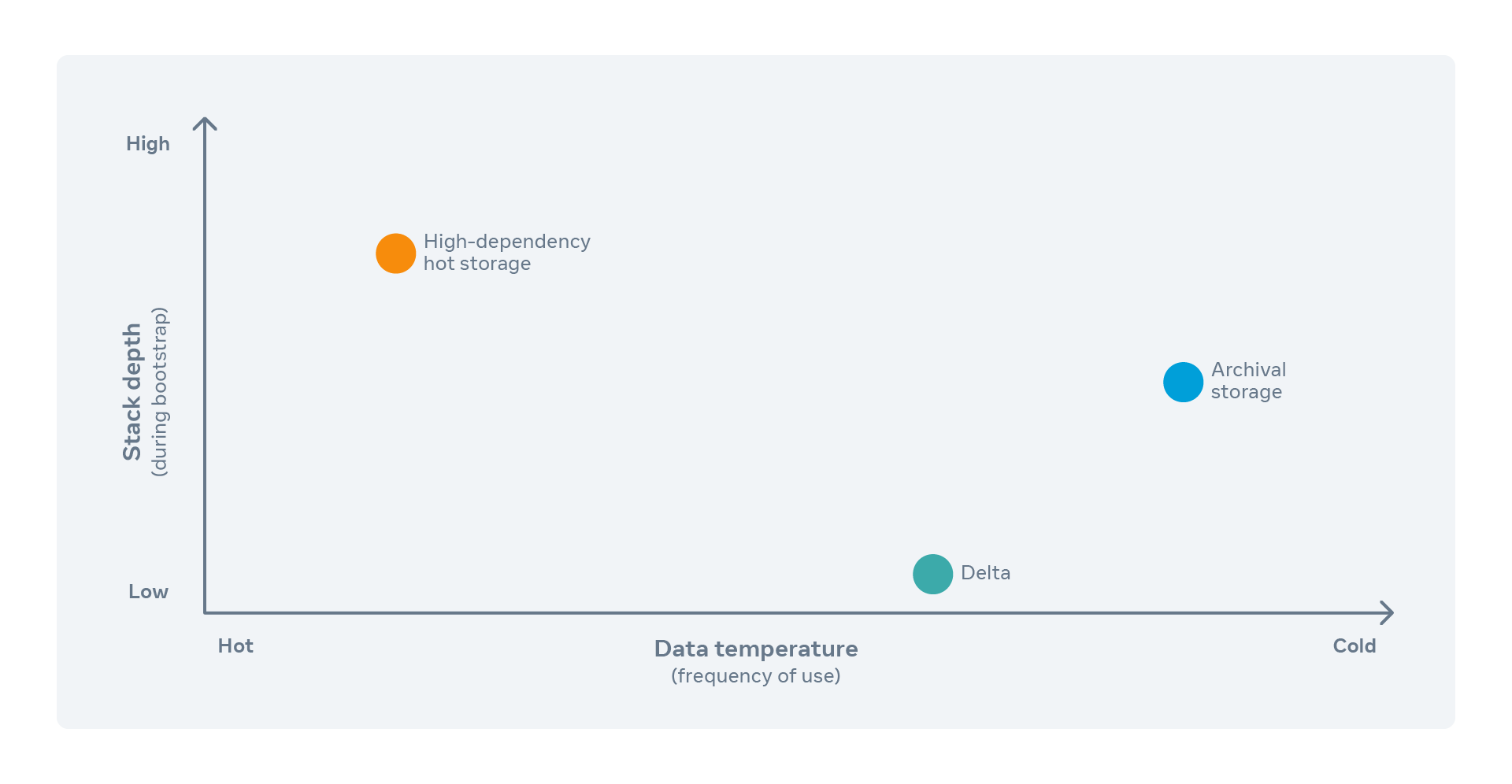 storage-system-cordinate-system.png
storage-system-cordinate-system.png
What are the architectural characteristics of Delta?
- Chain Replication
For data in a logical Bucket (the namespace of object storage), Delta first uses consistent hashing to partition the data into shards. For each shard, chain replication is used for redundancy. Typically, each shard has four replicas, and each replica is placed in a different fault domain.
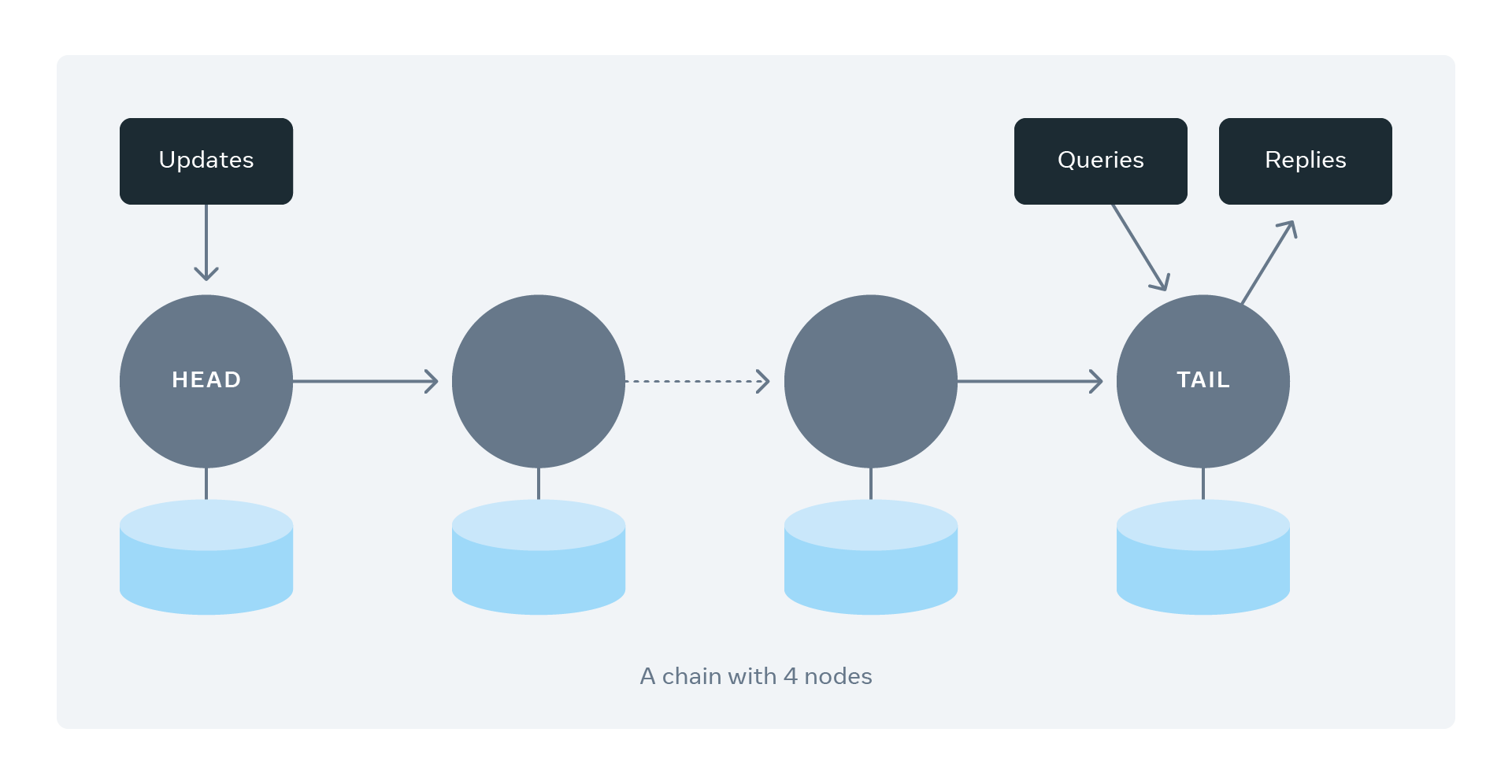 chain-with-4-nodes.png
chain-with-4-nodes.png
Read/Write flow: All writes go to the head of the chain and are replicated sequentially along the chain; success is returned only after the tail node has completed replication (synchronous replication). All reads are routed to the tail node to ensure strong consistency.
As can be seen, because writes are synchronous, Delta has relatively high write latency; because reads only go to the tail node, read throughput is also limited.
Of course, Delta does make a small optimization for reads — read offloading. That is, the client is allowed to read from any replica, but that replica must communicate with the tail node to confirm the clean version of the data before returning it to the client, to ensure consistency.
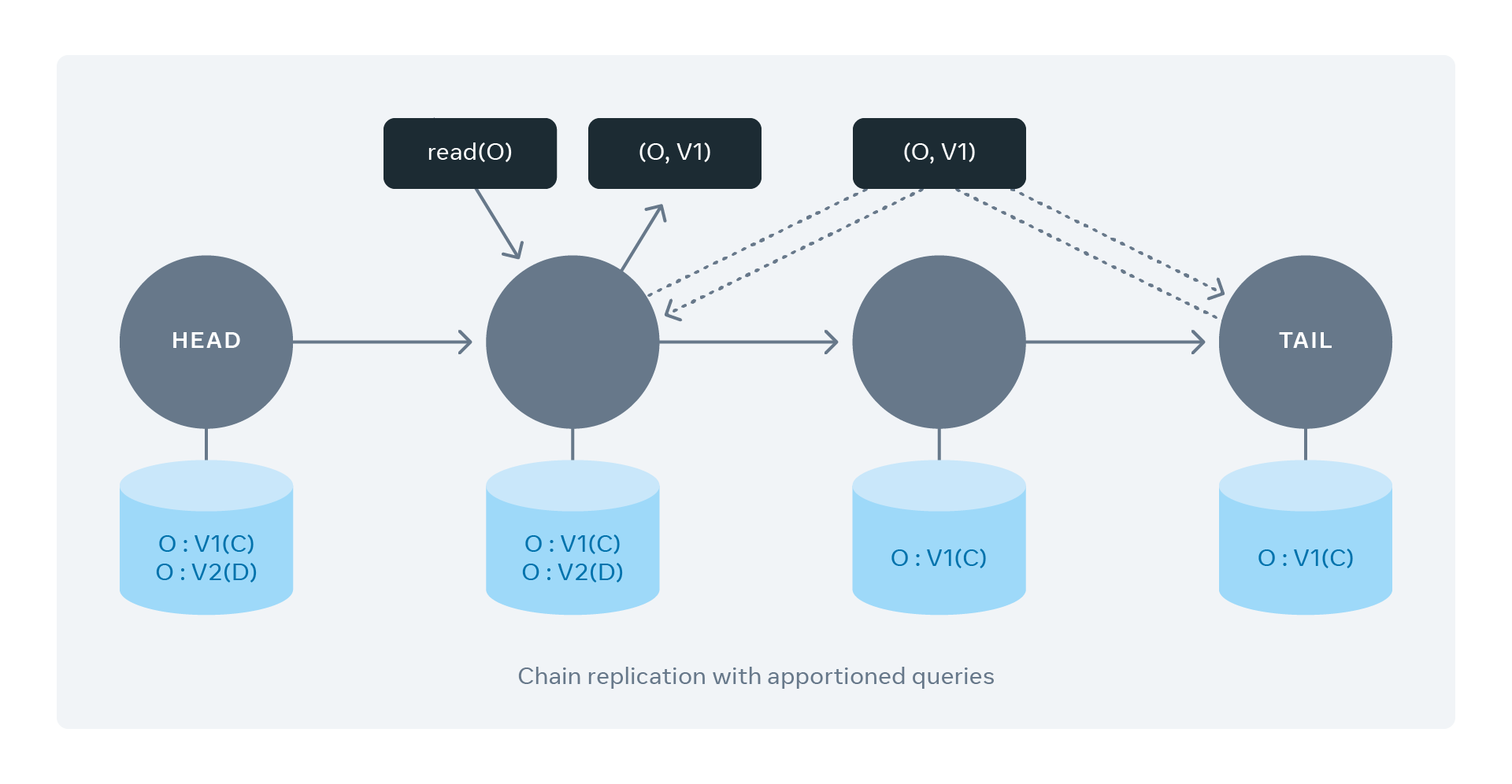 read-all-nodes.png
read-all-nodes.png
The rationale is that, compared to client queries, internal version confirmation queries are much lighter.
- Vote-based Removal and Tail Appending
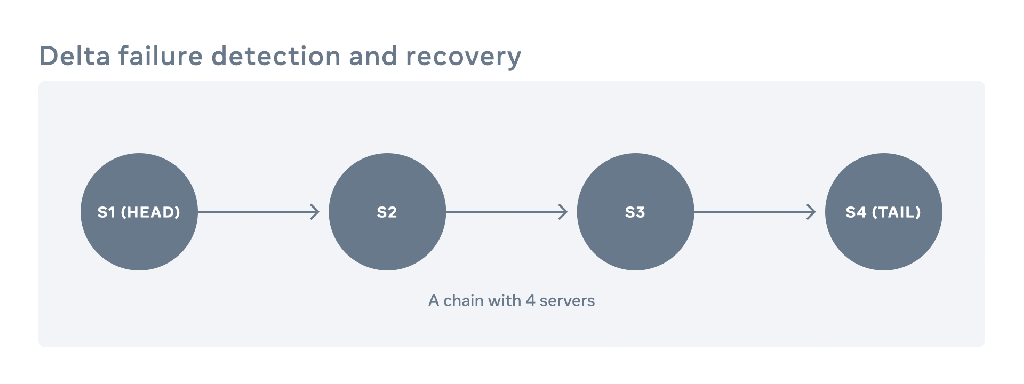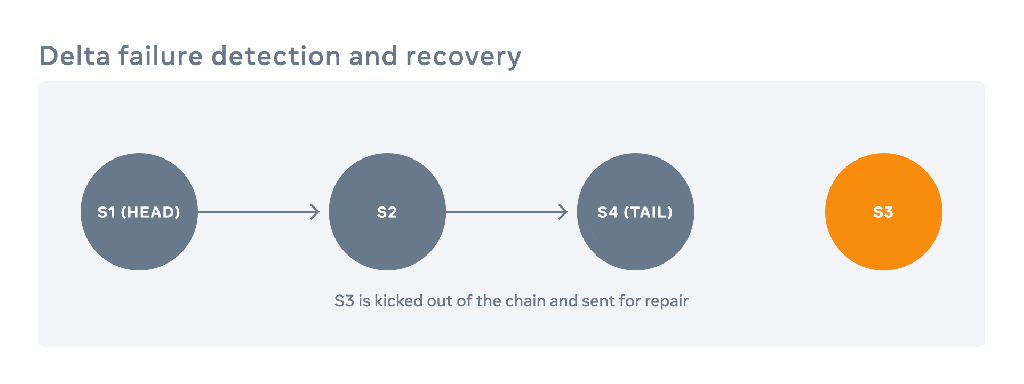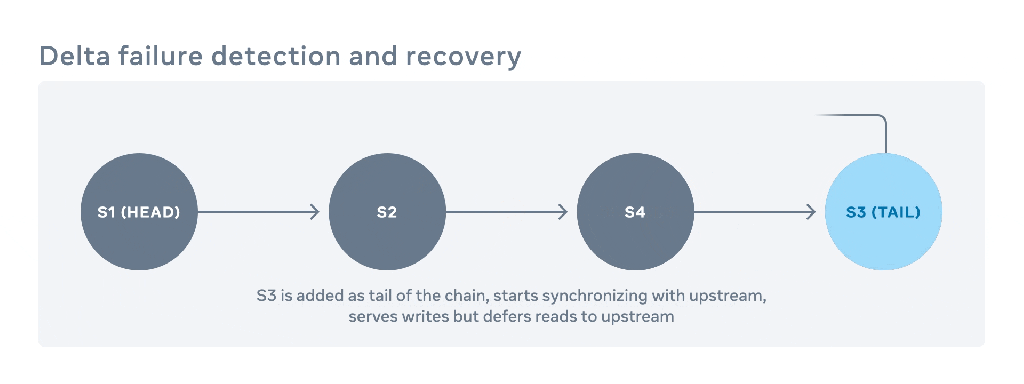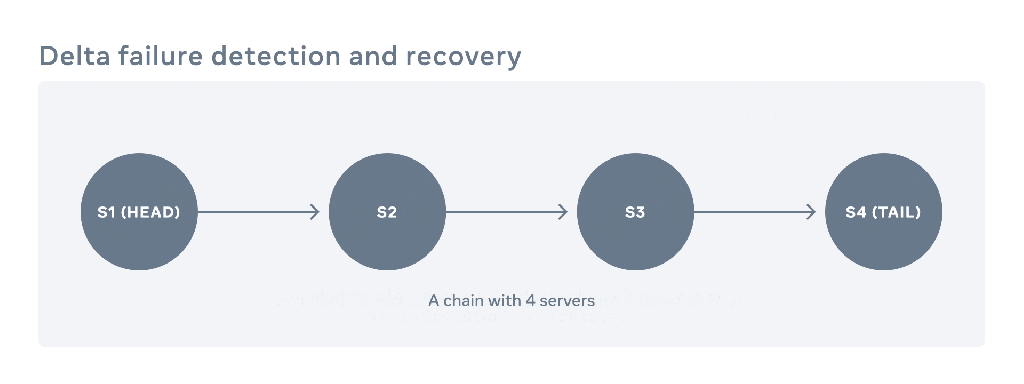
Delta removes failed nodes through heartbeats and voting: when a certain number of nodes simultaneously mark a node as having missed heartbeats, all replicas on that node are removed from the replication chain. Two thresholds need to be carefully chosen:
- Heartbeat timeout. If too short, it is overly affected by network jitter; if too long, it increases the write latency of the affected chain.
- Suspicion vote count. Setting it to 1 is clearly insufficient, because two nodes with poor network connectivity might vote each other out; too high is also bad, as it causes the failed node to remain in the chain for too long. Delta generally sets this to 2, paired with automated machine failure recovery.
After a failed node is repaired, its replica can be added back to the chain through the following steps:
- Re-append its replica to the end of the original chain.
- Read and synchronize data from the upstream node (the original tail).
- Route read requests to the upstream node until synchronization is complete.
- Become the new normal tail node after synchronization is finished.
 Delta-Visuals_v03-04.gif
Delta-Visuals_v03-04.gif
- Automated Repair
Delta uses a control plane service (CPS) to automatically repair failed nodes. Each CPS instance monitors a set of Delta Buckets. Its main strategies include:
- Maintaining a reasonable fault-domain distribution of replicas when repairing buckets.
- Ensuring an even distribution of replication chains across all servers to avoid localized overload.
- Preferring to repair rather than create new replicas when a replica is missing in a chain, to minimize data copying.
- Performing strict health checks on servers before adding them to a chain.
- Maintaining a pool of healthy servers, and only drawing a node from it when more than half the replicas in a chain have failed.
To explain the last point: repair if possible, and only allocate a new node from the pool when things are beyond repair (more than half failed), thereby ensuring the pool always has sufficient spare capacity.
The article also mentions global geographic replication and cold backup with an archival service. It notes that Delta’s next step is to serve as the storage backend for all Meta services that require data backup and recovery.

