The DDIA reading group shares the book chapter by chapter, supplemented with some details based on my experience with distributed storage and databases in industry. We share roughly every two weeks—welcome to join us. The schedule and all transcripts are here. We also have a corresponding distributed systems & database discussion group; notifications are sent there before each session. If you’d like to join, add me on WeChat: qtmuniao, give a brief self-introduction, and note “distributed systems group.” Also, my public account “Muniao Notes” has more articles on distributed systems, storage, and databases—feel free to follow.
The first part of this book discusses single-machine data systems; the second part discusses multi-machine data systems.
Replication means keeping multiple copies of the same data on different machines connected via a network. Its benefits are:
- Reduced latency: can be geographically close to users in different regions at the same time.
- Increased availability: can continue to provide service when parts of the system fail.
- Increased read throughput: smoothly scale out the machines available for queries.
This chapter assumes all data in our data system can fit on a single machine, so we only need to consider multi-machine replication. What if data exceeds single-machine scale? That’s what the next chapter addresses.
Author: Muniao Notes https://www.qtmuniao.com/2022/10/17/ddia-reading-chapter5 please indicate the source when reprinting
If data is read-only, replication is easy—just copy it to multiple machines. We can sometimes exploit this property using a divide-and-conquer strategy, splitting data into read-only and read-write parts; the read-only part then becomes much easier to replicate, and we can even use EC (erasure coding) for replication, reducing storage overhead while improving availability.
-
What does EC sacrifice?
Storage for computation.
But the difficulty lies in how to maintain multi-machine replication consistently when data is allowed to change. Commonly used replication control algorithms are:
- Single leader
- Multi-leader
- Leaderless
This involves trade-offs in multiple dimensions:
- Whether to use synchronous or asynchronous replication
- How to handle failed replicas
Database replication is not a new problem in academia, but in industry most people are newcomers—distributed databases have only been deployed at scale in industry in recent years.
Leaders and Followers
Each copy of redundantly stored data is called a replica. The main problem brought by multiple replicas is: how to ensure all data is synchronized to all replicas?
Leader-based synchronization algorithms are the most commonly used solution.
- One of the replicas is called the leader (also known as primary, master). The leader acts as the coordinator for writes; all writes must be sent to the leader.
- The other replicas are called followers (also known as read replicas, slaves, secondaries, hot-standby). After the leader writes changes locally, it sends them to each follower; the follower applies the changes to its own state machine after receiving them. This process is called the replication log or change stream.
- For reads, clients can read from both the leader and followers; but for writes, clients must send requests to the leader.
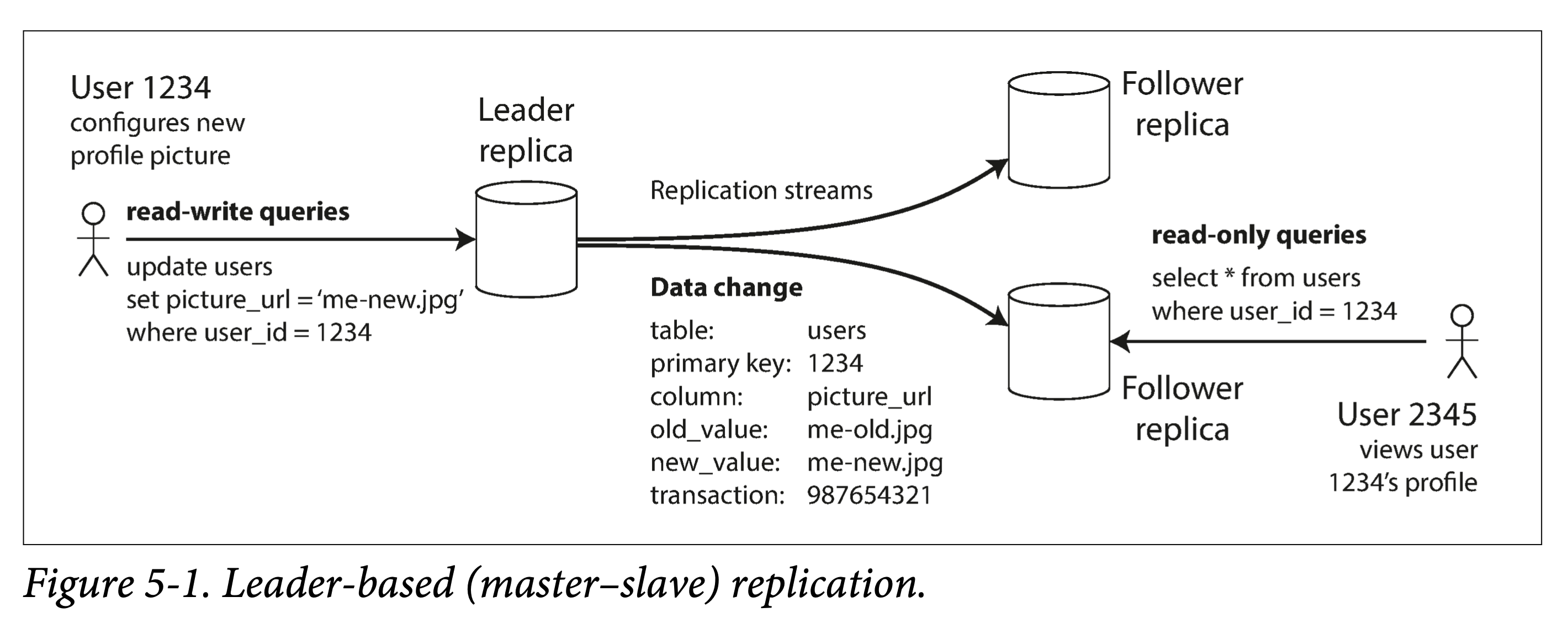 leader based replication
leader based replication
Following my habit, I will uniformly use leader and follower below.
Many data systems use this pattern:
- Relational databases: PostgreSQL (9.0+), MySQL, Oracle Data Guard, and SQL Server AlwaysOn
- Non-relational databases: MongoDB, RethinkDB, and Espresso
- Message queues: Kafka and RabbitMQ
Synchronous and Asynchronous Replication
The key difference between synchronous and asynchronous replication is: when is the request returned to the client?
- If it waits for a replica to finish writing, that replica is synchronously replicated.
- If it does not wait for a replica to finish writing, that replica is asynchronously replicated.
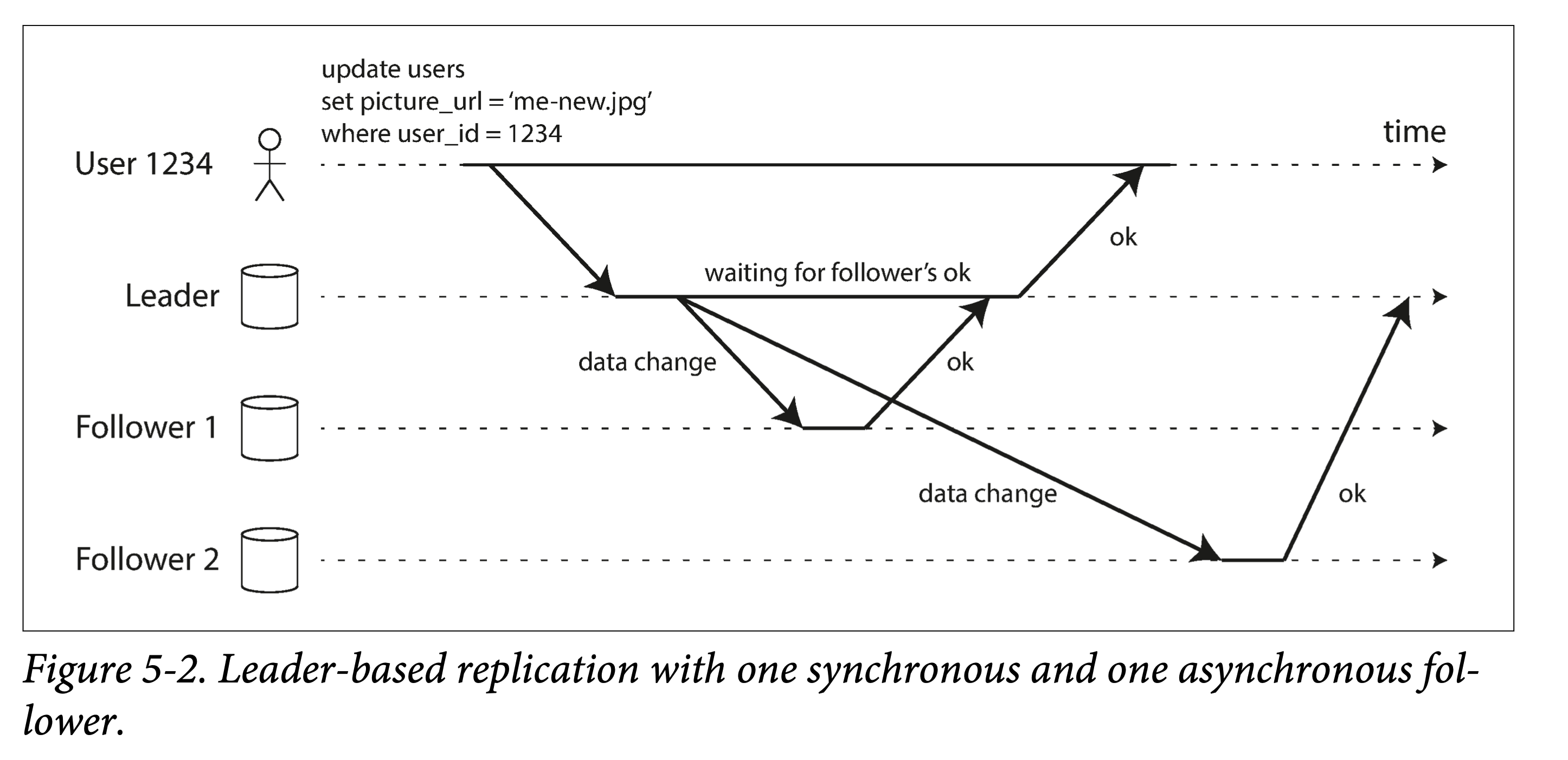 leader based sync and async
leader based sync and async
The comparison between the two is as follows:
- Synchronous replication sacrifices response latency and partial availability (writes cannot complete when some replicas have issues) in exchange for consistency across all replicas (though this cannot be strictly guaranteed).
- Asynchronous relaxes consistency in exchange for lower write latency and higher availability.
In practice, the choice depends on requirements for consistency and availability. For all followers, there are several options:
- Fully synchronous: all followers are written synchronously. If there are too many replicas, performance may suffer; of course, parallelization and pipelining can help.
- Semi-synchronous (semi-synchronous): some replicas are synchronous, others are asynchronous.
- Fully asynchronous: all followers are written asynchronously. If the network environment is good, this configuration can be used.
Asynchronous replication can cause serious problems such as lost replicas. In order to balance consistency and performance, academia has been continuously researching new replication methods, such as chain replication.
Multi-replica consistency and consensus have many connections, which will be discussed in later chapters of this book.
Adding New Replicas
In many cases, we need to add new replicas to an existing system.
If the original replica is read-only, a simple copy suffices. But if it is a writable replica, the problem becomes much more complicated. Therefore, a relatively simple solution is: prohibit writes, then copy. This is useful in some cases, such as when there is no write traffic at night and copying can definitely finish overnight.
If downtime is not acceptable, you can:
- The leader takes a consistent snapshot locally. What does consistent mean?
- Copy the snapshot to the follower node.
- Pull the operation log after the snapshot from the leader and apply it to the follower. How do we know the correspondence between the snapshot and subsequent logs? Sequence numbers.
- When the follower catches up with the leader, it can follow the leader normally.
This process is generally automated, such as in Raft; or it can be manual, such as writing some scripts.
Handling Failures
Any node in the system may fail, either planned or unplanned. How do we deal with these failures and maintain overall system availability?
Follower failure: catch-up recovery
Similar to adding a new follower. If it is far behind, it can directly pull a snapshot + logs from the leader; if it is only slightly behind, it can pull only the missing logs.
Leader failure: failover
This is relatively troublesome. First, a new leader must be elected, then all clients must be notified of the leader change. Specifically, it includes the following steps:
- Confirm leader failure. Prevent false positives caused by network jitter. Usually heartbeat-based liveness probes are used, with a reasonable timeout threshold; if the node’s heartbeat is not received after exceeding the threshold, the node is considered failed.
- Choose a new leader. The new leader can be produced through election (a consensus problem) or designation (an external control program). When choosing a leader, ensure the candidate’s data is as fresh as possible to minimize data loss.
- Let the system perceive the new leader. Other participants in the system include followers, clients, and the old leader. The first two are straightforward; for the old leader, when it recovers, some means must be used to let it know it has lost leadership, to avoid split brain.
Leader switching encounters many problems:
- Data conflict between old and new leaders. The new leader may not have synchronized all logs before taking over; after the old leader recovers, it may find data conflicts with the new leader.
- Conflicts with related external systems. That is, the new leader conflicts with external systems that use the replica’s data. The book gives the example of GitHub’s MySQL database conflicting with the Redis cache system.
- Role conflict between old and new leaders. That is, both the old and new leaders think they are the leader, called split brain. If both can accept writes and there is no conflict resolution mechanism, data will be lost or corrupted. Some systems will shut down one of the replicas after detecting split brain, but poor design may shut down both leaders.
- Timeout threshold selection. If the timeout threshold is too small, in an unstable network environment (or when the leader is heavily loaded), it may cause frequent leader switching; if it is too large, failover cannot be performed in time, and recovery time increases, causing prolonged service unavailability.
All the above problems may have different solutions depending on requirements, environment, and time. Therefore, in the early stages of system deployment, many operations teams prefer to perform switching manually; after accumulating some experience, they gradually automate it.
Node failures; unreliable networks; trade-offs between consistency, durability, availability, and latency; these are all fundamental problems faced when designing distributed systems. Making artistic trade-offs on these issues according to actual circumstances is the beauty of distributed systems.
Replication Logs
In databases, how is leader-based multi-replica implemented? There are multiple methods at different levels, including:
- Statement-level replication
- Write-ahead log replication
- Logical log replication
- Trigger-based replication
For a system, what does multi-replica synchronization synchronize? Incremental changes.
Specifically, for a data system composed of a database, it usually consists of an application layer outside the database, a query layer inside the database, and a storage layer. Changes are expressed at the query layer as statements; at the storage layer as storage-engine-related write-ahead logs and storage-engine-independent logical logs; after changes are completed, they are expressed at the application layer as trigger logic.
Statement-Based Replication
The leader records all update statements: INSERT, UPDATE, or DELETE, and sends them to the followers. The leader here acts similarly to a pseudo-client for the other followers.
But this method has some problems:
- Statements with nondeterministic functions may cause different changes on different replicas, such as
NOW(),RAND(). - Using auto-increment columns or depending on existing data. Then statements from different users must be executed in exactly the same order; when there are concurrent transactions, different execution orders may lead to replica inconsistency.
- Statements with side effects (triggers, stored procedures, UDFs) may produce different side effects on different replicas due to different contexts, unless the side effects are deterministic outputs.
Of course, there are solutions:
- Identify all statements that produce nondeterministic results.
- For these statements, synchronize values rather than statements.
But there are too many corner cases; step 1 requires considering too many situations.
Shipping the Write-Ahead Log (WAL)
We find that mainstream storage engines have a write-ahead log (WAL, for crash recovery):
- For the log-structured camp (LSM-Tree, such as LevelDB), each modification is first written to a log file to prevent data loss in the MemTable.
- For the in-place update camp (B+ Tree), each modification is first written to the WAL for crash recovery.
All user-level changes ultimately land in the storage engine as state, and the storage engine usually maintains a structure that is:
- Append-only
- Replayable
This structure is naturally suitable for backup synchronization. Essentially, this is because the disk read/write characteristics are similar to the network: disks are more efficient with sequential writes, and networks only support streaming writes. Specifically, when the leader writes to the WAL, it simultaneously sends the corresponding log over the network to all followers.
The book mentions a database version upgrade problem:
- If the old version code is allowed to send logs to the new version code (backward compatibility should naturally be achieved), this is forward compatibility. In this case, during upgrades, you can first upgrade the followers, then switch and upgrade the leader.
- Otherwise, the only option is a downtime upgrade.
Logical Log Replication (Row-Based)
To decouple from the specific storage engine physical format, a different log format can be used for data synchronization: logical log.
For relational databases, the row is a suitable granularity:
- For inserted rows: the log needs to contain all column values.
- For deleted rows: the log needs to contain the identifier of the row to be deleted, which can be the primary key or any other information that can uniquely identify the row.
- For updated rows: the log needs to contain the identifier of the row to be updated, and all column values (or at least the column values to be updated).
For multi-row modifications, such as transactions, a transaction commit record can be added after the modifications. MySQL’s binlog works this way.
The benefits of using logical logs are:
- Convenient compatibility between old and new version code, enabling better rolling upgrades.
- Allows different replicas to use different storage engines.
- Allows exporting changes for various transformations, such as exporting to a data warehouse for offline analysis, building indexes, adding caches, etc.
I previously analyzed an interesting article on unifying various data systems based on logs.
Trigger-Based Replication
The methods described above all perform multi-replica synchronization inside the database.
But in some cases, user decisions may be needed on how to replicate data:
- Filter the data to be replicated, replicating only a subset.
- Replicate data from one type of database to another.
Some databases such as Oracle provide tools. For others, triggers and stored procedures can be used—that is, hooking user code into the database for execution.
Trigger-based replication has poorer performance and is more error-prone; but it gives users more flexibility.
Replication Lag Problems
As mentioned above, the benefits of using multiple replicas are:
- Availability: tolerate partial node failures
- Scalability: add read replicas to handle more read requests
- Low latency: let users choose a nearby replica to access
For read-heavy, write-light scenarios, one might imagine that read traffic can be spread out by aggressively adding read replicas. But there is an implicit condition: synchronization among multiple replicas must be asynchronous; otherwise, as read replicas increase, some replicas are prone to failure, which would block writes.
But if replication is asynchronous, inconsistency is introduced: some replicas lag behind the leader.
If there are no more writes, after some time, the multiple replicas will eventually reach consistency: eventual consistency.
In practice, networks are usually fast, so replication lag is not long, meaning this eventually is usually not long, such as millisecond level, at most second level. However, for distributed systems, no one dares to guarantee that, due to network partitions, high machine load, and other hardware and software issues, in extreme cases this eventually can be very long.
In short, eventually is a very imprecise qualifier.
For such eventually consistent systems, in engineering, one must consider the consistency problems caused by replication lag.
Read-After-Write
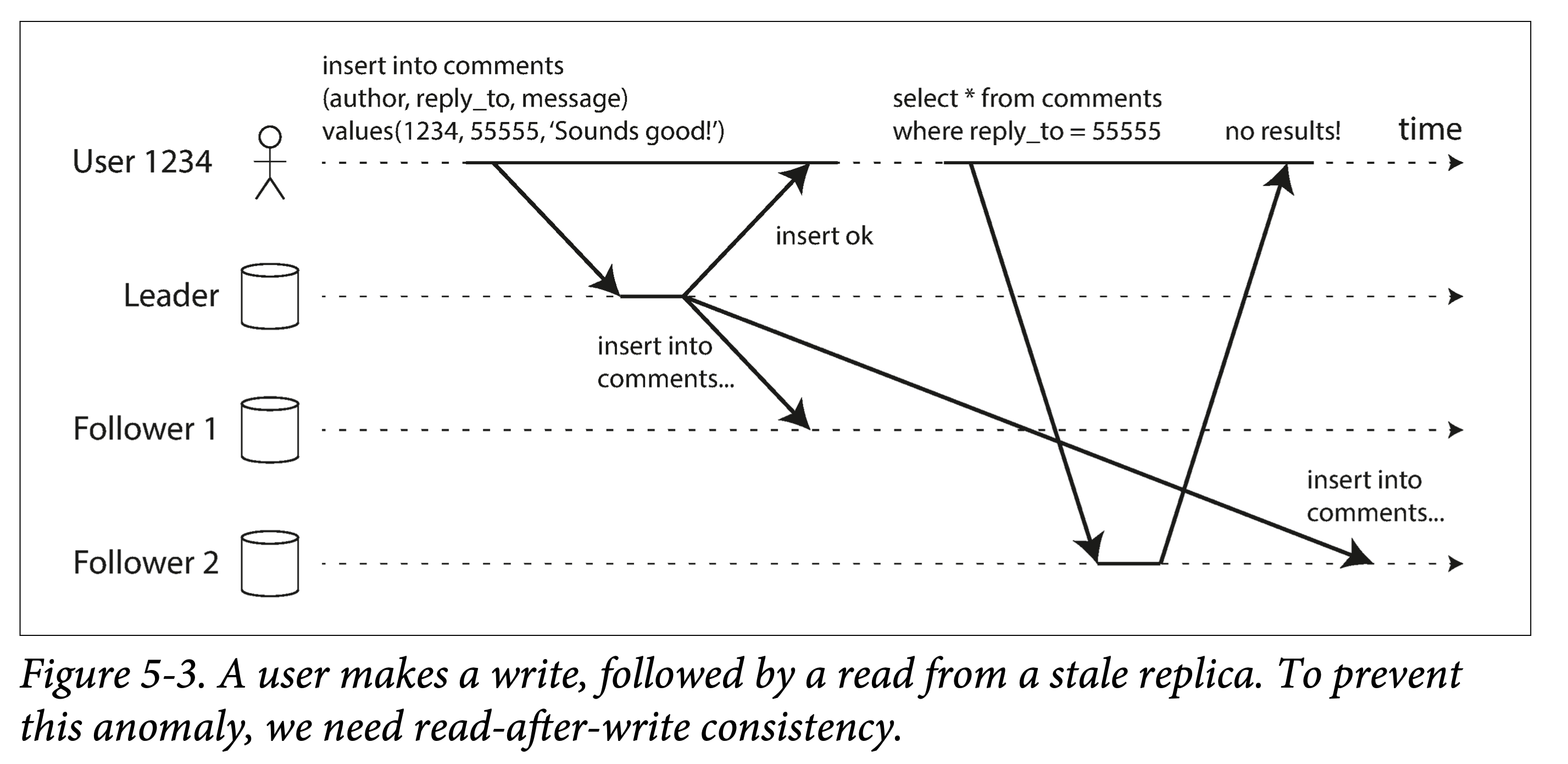 read after write
read after write
The problem in the above figure is that, in an asynchronously replicated distributed database, the same client writes to the leader and returns; shortly after, it reads a lagging follower, and finds: it cannot read what it just wrote!
To avoid such counter-intuitive occurrences, we introduce a new consistency: read-after-write consistency, or read-your-writes consistency.
If the database provides this consistency guarantee, for a single client, it is certain to be able to read the changes it wrote. That is, this consistency is a form of causal consistency from the perspective of a single client.
So how to provide this guarantee, or implement this consistency? Several solutions are listed:
- Classify by content. For the set of content that the client may modify, read only from the leader. For example, for personal profiles on a social network, read your own profile from the leader; but when reading others’ profiles, you can read from followers.
- Classify by time. If each client can access almost all data, then option 1 degenerates into all data having to be read from the leader, which is clearly unacceptable. In this case, you can discuss by time: data that has been recently modified is read from the leader; other data is read from followers. How to choose the time threshold (e.g., one minute) for distinguishing recent? You can monitor the maximum lag of followers over a period of time and set it based on this empirical value.
- Use timestamps. The client records the timestamp of its last modification; when reading from a follower, it uses this timestamp to check whether the follower has already synchronized the content before that timestamp. You can find a follower that has synchronized among all replicas; or block and wait for a follower to synchronize to that timestamp before reading. Timestamps can be logical timestamps or physical timestamps (in which case multi-machine clock synchronization is very important).
There will be some actual complex cases:
- Data is distributed across multiple physical data centers. All requests that need to be sent to the leader must first be routed to the data center where the leader is located.
- A logical user has multiple physical clients. For example, a user accesses via computer and mobile phone simultaneously; in this case, device IDs cannot be used, and user IDs must be used to guarantee read-your-writes consistency from the user’s perspective. But different devices have different physical timestamps, and different devices may be routed to different data centers when accessing.
Monotonic Reads
Another problem that asynchronous replication may bring: for a client, the system may experience moving backward in time.
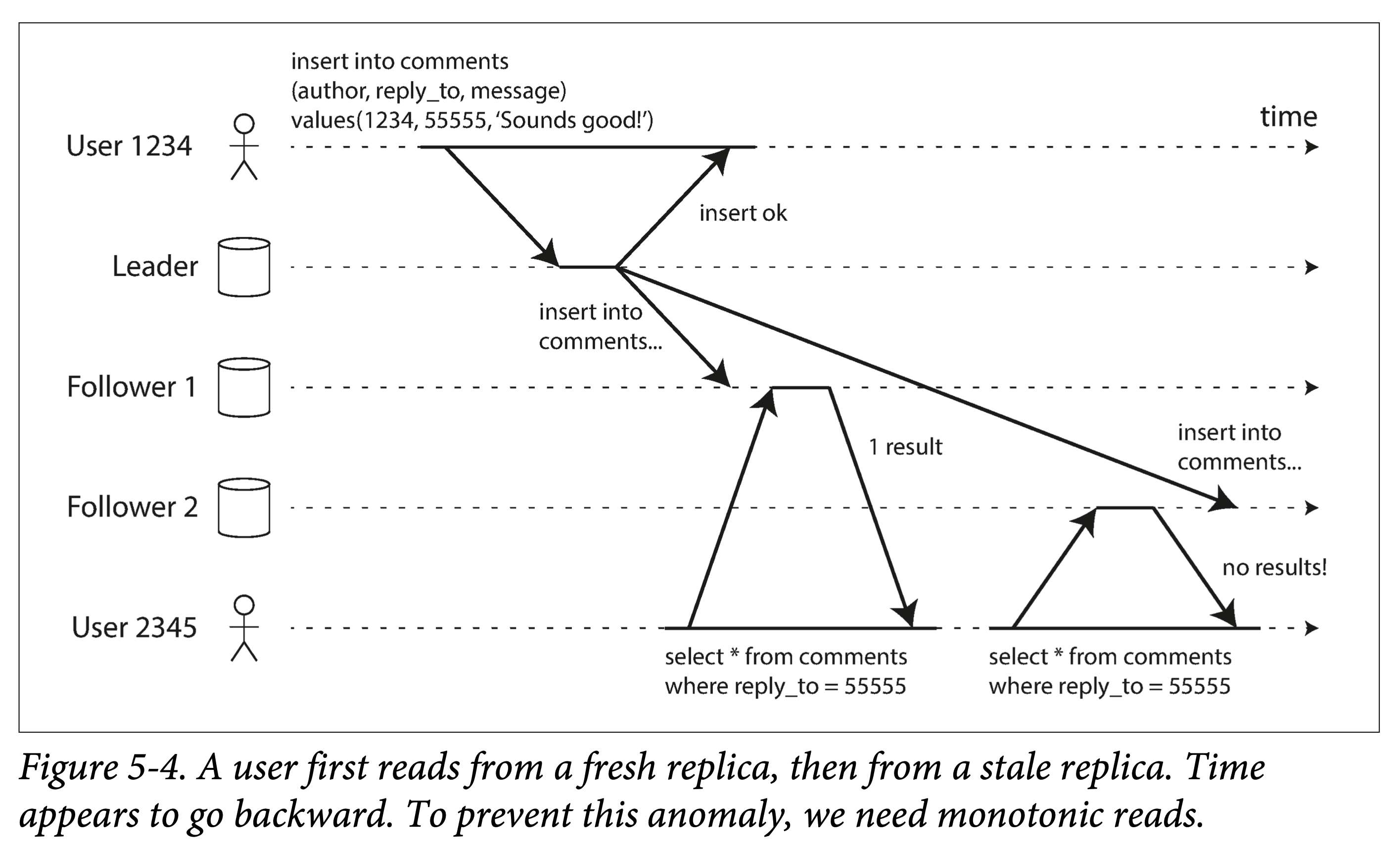 monotonic reads
monotonic reads
Thus, we introduce another consistency guarantee: monotonic reads.
-
What is the difference between read-your-writes consistency and monotonic reads?
Read-after-write guarantees the write-then-read order; monotonic reads guarantee the order between multiple reads.
How to implement monotonic reads?
- Read data from only one replica.
- The timestamp mechanism mentioned above.
Consistent Prefix Reads
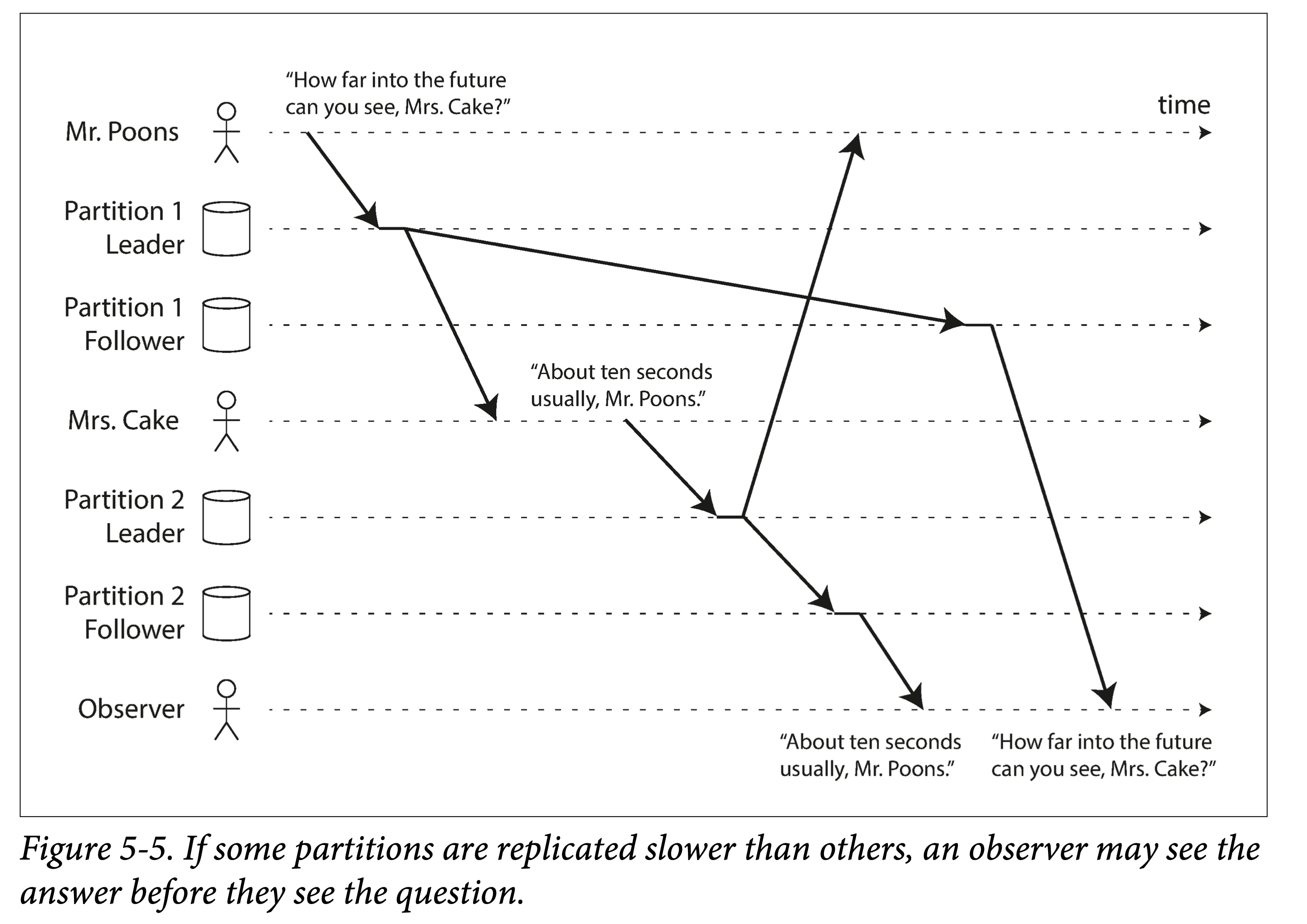 lower partition
lower partition
A third problem brought by asynchronous replication: sometimes causality is violated.
The essence is: if the database consists of multiple partitions, and the event order across partitions cannot be guaranteed. In this case, if two causally related events land in different partitions, the effect may appear before the cause.
To prevent this problem, we introduce another consistency: consistent prefix reads. A strange name.
Methods to implement this consistency guarantee:
- Do not partition.
- Route all causally related events to a single partition.
But tracking causality is a difficult problem.
The Ultimate Solution to Replication Lag
Transactions!
The consistency problems brought by multi-replica asynchronous replication can all be solved by transactions. Single-machine transactions have existed for a long time, but as databases move into the distributed era, many NoSQL systems initially abandoned transactions.
- Why?
- Easier to implement. 2. Better performance. 3. Better availability.
Thus, complexity was shifted to the application layer.
This was a compromise when database systems first stepped into the distributed era (multi-replica, multi-partition); after enough experience has been accumulated, transactions will inevitably be brought back.
Thus, more and more distributed databases have begun to support transactions in recent years, known as distributed transactions.
Multi-Leader Model
The biggest problem with the single-leader model: all writes must go through it; if for any reason the client cannot connect to the leader, it cannot write to the database.
So the natural thought arises: can multi-leader work?
Multi-leader replication: there are multiple leaders that can accept writes; each leader, after receiving a write, forwards it to all other replicas. That is, a system with multiple write points.
Multi-Leader Application Scenarios
In a single data center, the multi-leader model is not very meaningful: the complexity outweighs the benefits. Overall, due to consistency and other issues, multi-leader model application scenarios are relatively few, but there are some scenarios where it fits well:
- Databases span multiple data centers
- Clients that need to work offline
- Collaborative editing
Multiple Data Centers
Suppose a database’s replicas span multiple data centers; if the single-leader model is used, write latency will be high. Can each data center have its own leader?
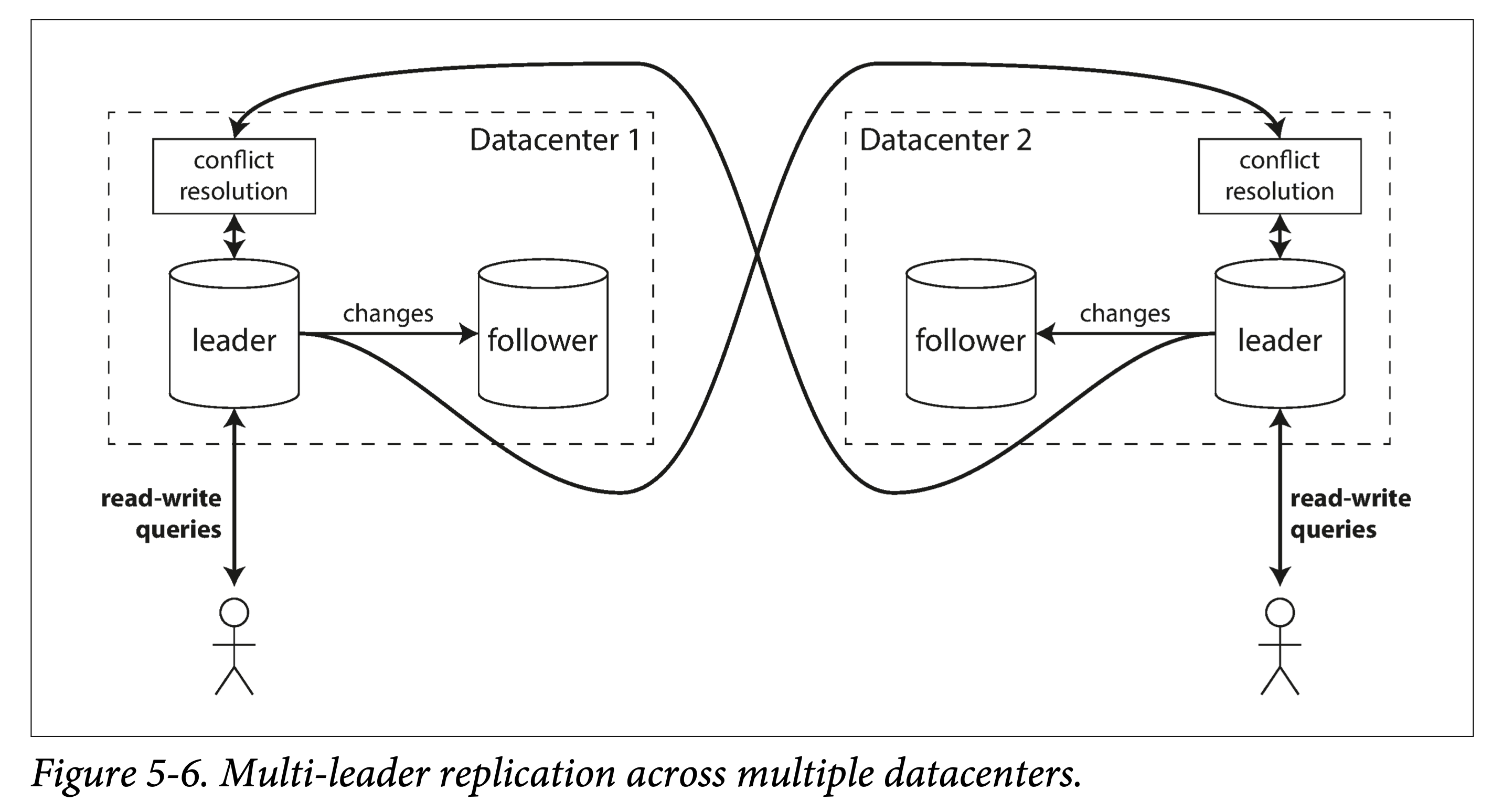 multi-leader across multiple data centers
multi-leader across multiple data centers
Comparison of single-leader and multi-leader in multi-data-center scenarios:
| Comparison Item | Single-Leader Model | Multi-Leader Model |
|---|---|---|
| Performance | All writes must be routed to one data center | Writes can be local |
| Availability | If the data center housing the leader fails, a leader switch is needed | Each data center can operate independently |
| Network | Cross-data-center writes are more sensitive to network jitter | Asynchronous replication between data centers is more tolerant of public network failures |
But the multi-leader model has serious defects in consistency: if two data centers modify the same data simultaneously, write conflicts must be resolved reasonably. In addition, for databases, multi-leader makes it difficult to guarantee consistency of auto-increment primary keys, triggers, and integrity constraints. Therefore, in engineering practice, multi-leader is used relatively infrequently.
Offline Clients
Multiple device clients of an application that allows continued writing while offline, such as a calendar app. If you add events on your computer and phone while offline, then when the devices are online, they need to synchronize data with each other.
Multiple replicas that continue to work after going offline are essentially a multi-leader model: each leader can independently write data, and then resolve conflicts after network connectivity is restored.
But how to support normal offline operation and graceful conflict resolution after going online is a difficult problem.
One feature of Apache CouchDB is its support for the multi-leader model.
Collaborative Editing
Online collaboration applications like Google Docs are becoming increasingly popular.
Such applications allow multiple people to simultaneously edit documents or spreadsheets; the underlying principles are very similar to the offline clients discussed in the previous section.
To achieve collaboration and resolve conflicts, you can:
- Pessimistic approach. Lock to avoid conflicts, but the granularity needs to be as small as possible, otherwise multiple people cannot simultaneously edit the same document.
- Optimistic approach. Allow each user to write blindly, and if there are conflicts, let the user resolve them.
Git is also a similar protocol.
Handling Write Conflicts
The biggest problem with the multi-leader model is: how to resolve conflicts.
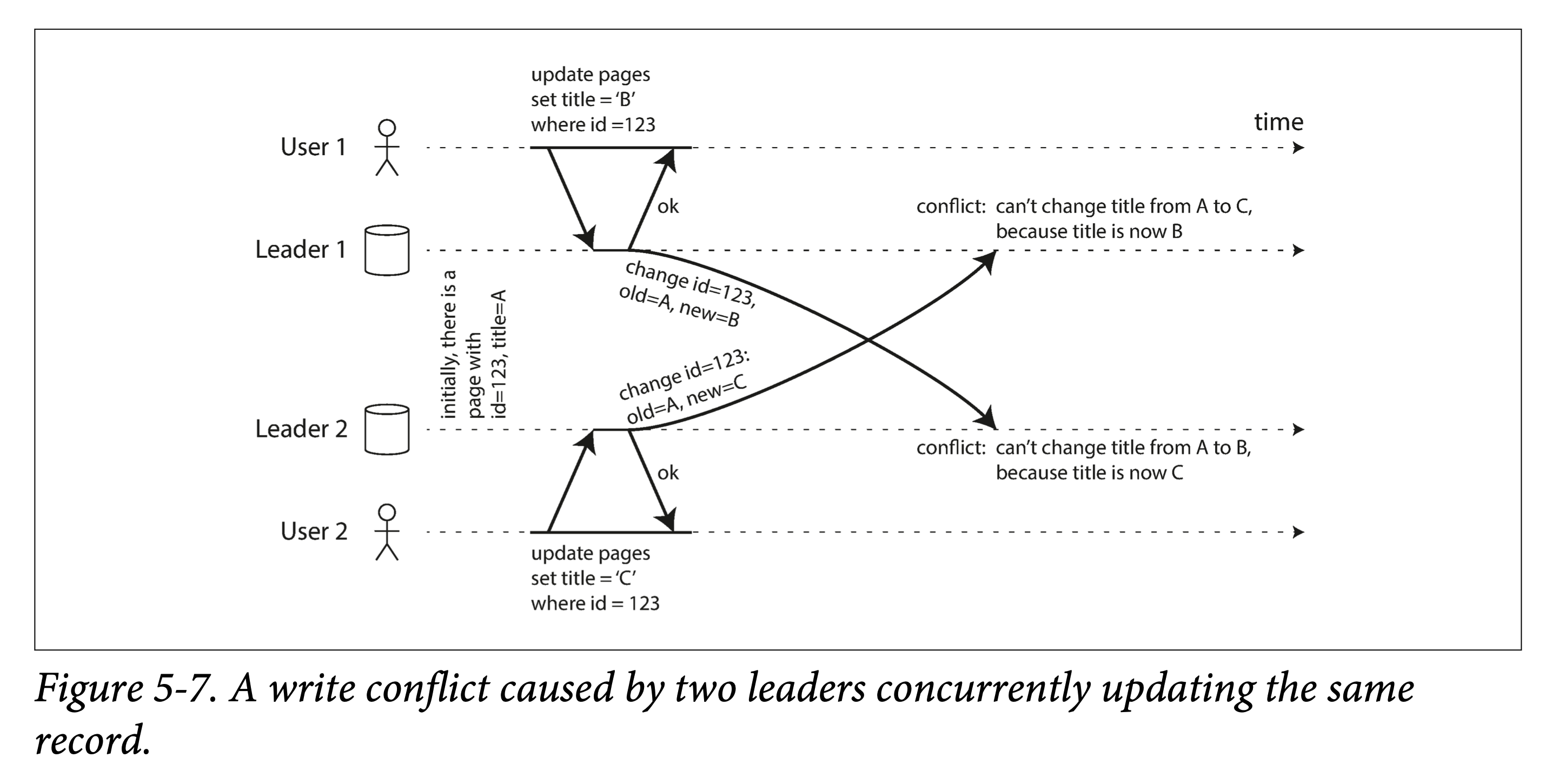 write conflict
write conflict
Consider modifying the title of a wiki page:
- User 1 changes the page title from A to B
- User 2 changes the page title from A to C
Both operations succeed locally, and then during asynchronous synchronization, a conflict occurs.
Conflict Detection
Conflicts can be detected in synchronous or asynchronous ways.
For the single-leader model, when a conflict is detected, because there is only one leader, conflicts can be detected synchronously and thus resolved:
- Let the second write block until the first write completes.
- Let the second write fail and retry.
But for the multi-leader model, two writes may succeed immediately on different leaders. Then during asynchronous synchronization, the conflict is discovered, but it is too late (there is no simple way to decide how to resolve the conflict).
Although you can use a synchronous approach to write to all replicas before returning the request to the client among multiple leaders. But this loses the main advantage of the multi-leader model: allowing multiple leaders to independently accept writes. At this point, it degenerates into the single-leader model.
Conflict Avoidance
The best way to resolve conflicts is to avoid them in design.
Since the multi-leader model has great complexity in resolving conflicts after they occur, conflict-avoiding designs are often used.
Suppose your dataset can be divided into multiple partitions, with the leader for different partitions placed in different data centers; then from the perspective of any single partition, it becomes a single-leader model.
For example: for an application serving global users, each user is fixedly routed to a nearby data center. Then, each user’s information has a unique leader.
But if:
- A user moves from one location to another
- A data center is damaged, causing routing changes
These pose challenges to this design.
Conflict Convergence
In the single-leader model, all events are relatively easy to order, so we can always use the later write to overwrite the earlier write.
But in the multi-leader model, many conflicts cannot be ordered: from the perspective of each leader, the event order is inconsistent, and neither is more authoritative, so it is impossible to make all replicas eventually converge.
At this point, we need some rules to make them converge:
- Give each write a sequence number, and the later one wins. Essentially, this uses an external system to order all events. But this may cause data loss. For example, for an account with 10 yuan, client A subtracts 8, client B subtracts 3; either succeeding individually would be problematic.
- Give each replica a sequence number; replicas with higher sequence numbers have higher priority. This also causes data loss on lower-sequence-number replicas.
- Provide an automatic way to merge conflicts. For example, if the result is a string, it can be sorted and joined with a separator; in the previous wiki conflict, the merged title would be “B/C”.
- Use a program to customize a conflict resolution strategy that preserves all conflicting value information. This customization can also be handed over to the user.
Custom Resolution
Since only the user knows the information about the data itself, a better approach is to leave how to resolve conflicts to the user. That is, allow users to write callback code providing conflict resolution logic. This callback can be executed:
- At write time. When a conflict is discovered during writing, call the callback code, resolve the conflict, and then write. This code usually runs in the background and cannot block, so it cannot synchronously notify the user at call time. But logging is still possible.
- At read time. When a write conflict occurs, all conflicts are preserved (e.g., using multi-versioning). Next time it is read, the system returns all data versions to the user for interactive or automatic conflict resolution, and writes the result back to the system.
The above conflict resolution is limited to the level of a single record, row, or document.
TODO (automatic conflict resolution)
Defining Conflicts
Some conflicts are obvious: concurrent writes to the same key.
Some conflicts are more subtle. Consider a meeting room reservation system. Reserving the same meeting room does not necessarily cause a conflict; only when the reserved time periods overlap is there a conflict.
Multi-Leader Replication Topologies
Replication topology describes the propagation path of data writes from one node to another.
When there are only two leaders, the topology is determined, as shown in Figure 5-7. Leader1 and Leader2 must both send data to each other. But as the number of replicas increases, there are multiple choices for the data replication topology, as shown below:
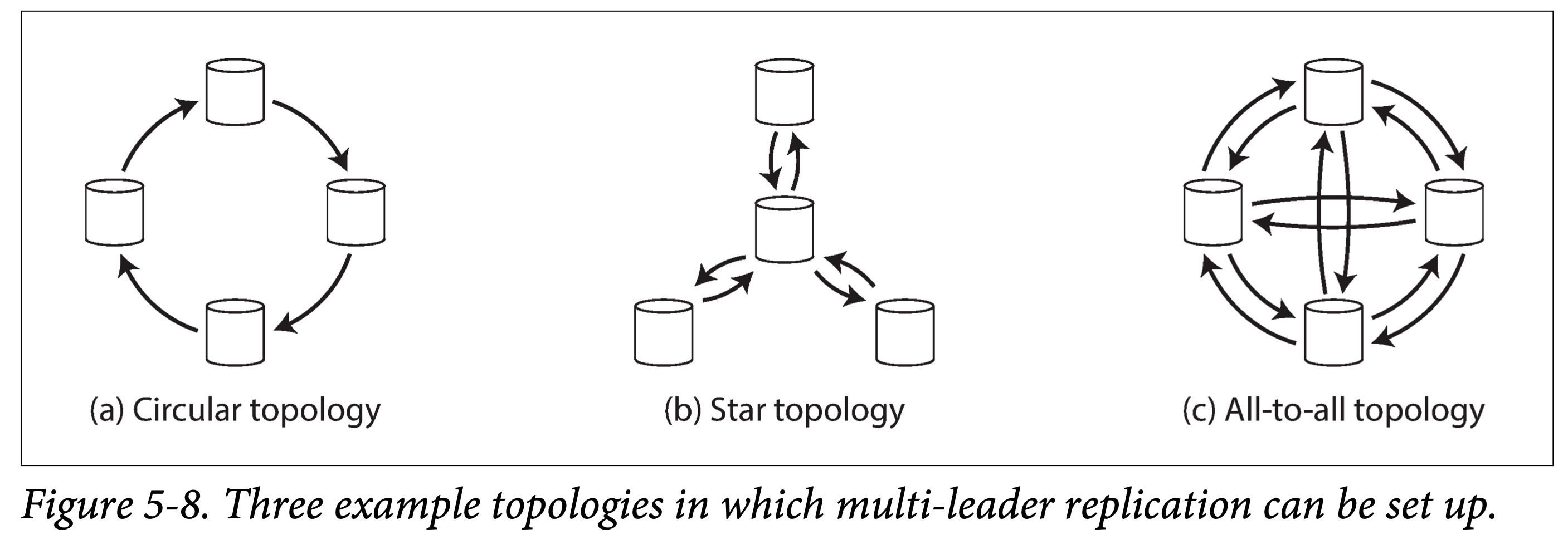 multi-leader topologies
multi-leader topologies
The above figure shows common replication topologies when there are ≥ 4 leaders:
- Circular topology. Fewer communication hops, but when forwarding, information about predecessor nodes in the topology must be carried. If one node fails, the replication chain may be interrupted.
- Star topology. The central node is responsible for receiving and forwarding data. If the central node fails, the entire topology is paralyzed.
- All-to-all topology. Every leader sends data to all remaining leaders. Higher communication link redundancy, better fault tolerance.
For circular and star topologies, to prevent broadcast storms, each node needs to be tagged with a unique identifier (ID); when receiving data originating from itself sent by others, it must promptly discard it and stop propagation.
All-to-all topology also has its own problems: especially when all replication links have inconsistent speeds. Consider the following example:
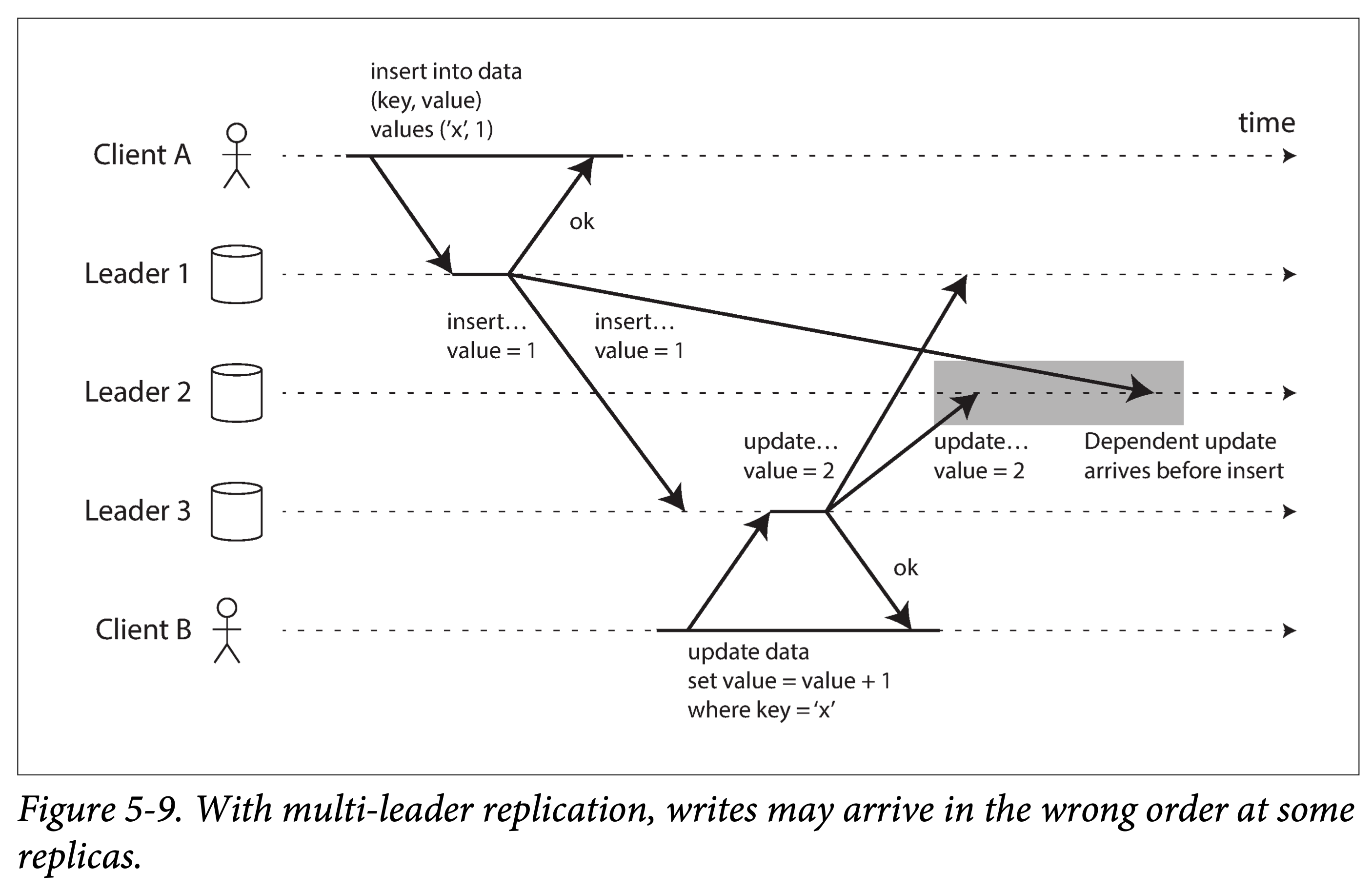 writes wrong order
writes wrong order
Two statements with causal dependencies (insert first, then update), when replicated to Leader 2, due to different speeds, cause it to receive data that violates causal consistency.
To globally order these write events, using each leader’s physical clock alone is insufficient, because physical clocks:
- May not be sufficiently synchronized
- May regress during synchronization
A strategy called version vectors can be used to order events across multiple replicas and solve causal consistency problems. The next section will discuss this in detail.
Final advice: if you are going to use a multi-leader-based system, you must be aware of the problems mentioned above, do more testing, and ensure that the guarantees it provides match your usage scenario.
Leaderless Model
In leader-based models, the leader determines the write order; followers do not directly interact with clients for writes, but simply replay the write order of their corresponding leader (or you can understand the leader as acting as a client for the followers).
The leaderless model, on the other hand, allows any replica to accept writes.
In the relational database era, the leaderless model was almost forgotten. Starting from Amazon’s Dynamo paper, the leaderless model has shone brightly again; Riak, Cassandra, and Voldemort were all inspired by it, and can be collectively called the Dynamo-style systems.
Curiously, Amazon’s database product DynamoDB is not the same thing as Dynamo.
Generally, in the leaderless model, writes can be:
- Written directly to replicas by the client.
- Received by a coordinator, which forwards them to multiple replicas. But unlike a leader, the coordinator is not responsible for ordering.
Writing When Nodes Have Failed
In leader-based models, when a replica fails, failover is needed.
But in the leaderless model, you can simply ignore it.
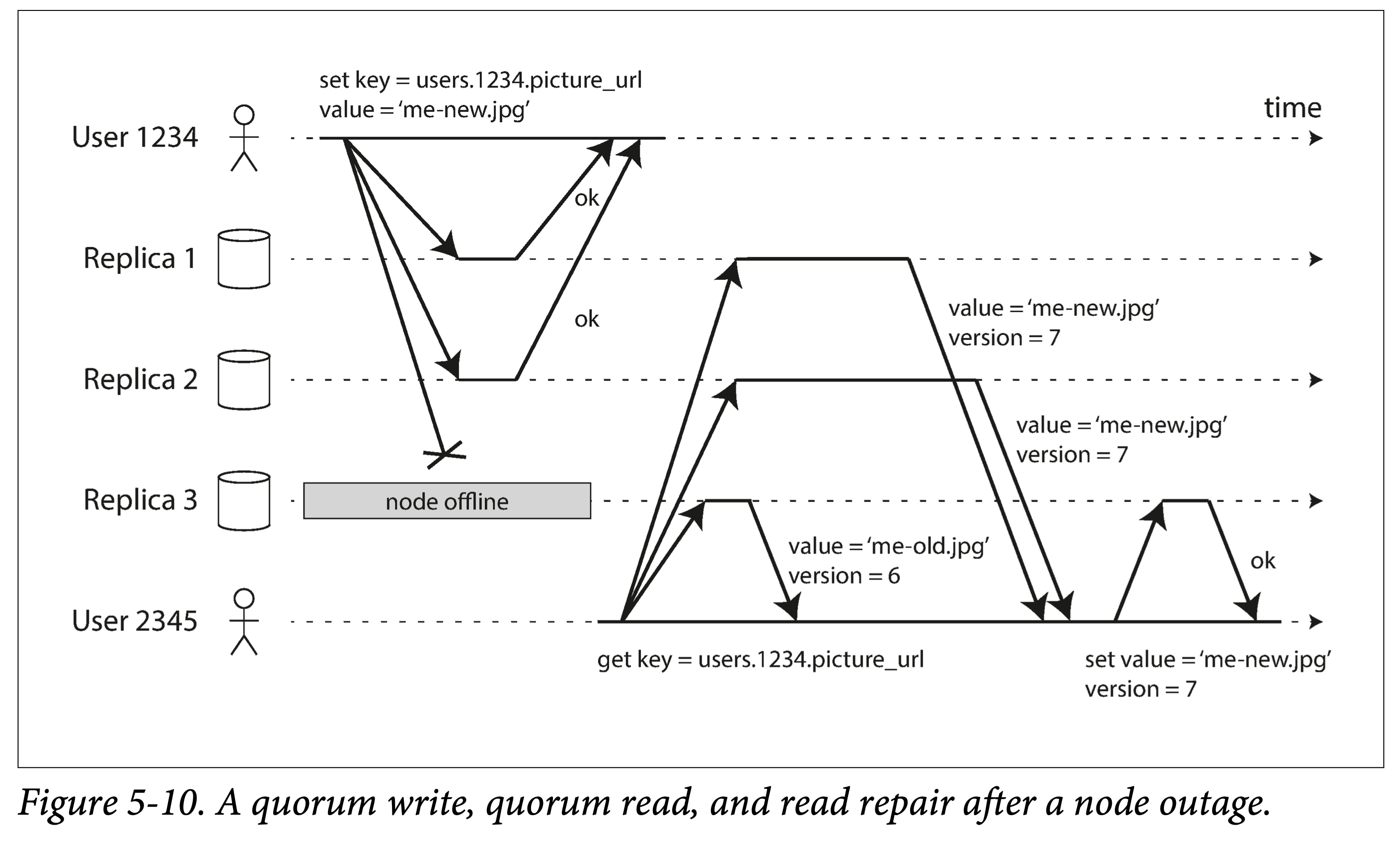 quorum write
quorum write
Quorum write, quorum read, and read repair.
Since writes simply ignore failed replicas; reads must do more: read multiple replicas simultaneously, and pick the latest version.
Read Repair and Anti-Entropy
Leaderless models also need to maintain consistency among multiple replicas. After some nodes crash and restart, how do they make up for missed data?
Dynamo-style storage usually has two mechanisms:
- Read repair, essentially a piggybacked repair—when reading, if old data is found, it is repaired on the fly.
- Anti-entropy process, essentially a catch-all repair. Read repair cannot cover all stale data, so some background processes are needed to continuously scan, find stale data, and update it. This blog post has an expanded description of this term.
Quorum Reads and Writes
If the total number of replicas is n, writing to w replicas is considered a successful write, and at least r nodes must be read when querying. As long as w + r > n, we can read the latest data (pigeonhole principle). The values of r and w are then called quorum reads and writes—that is, this constraint is the minimum (quorum) number of votes required to ensure data validity.
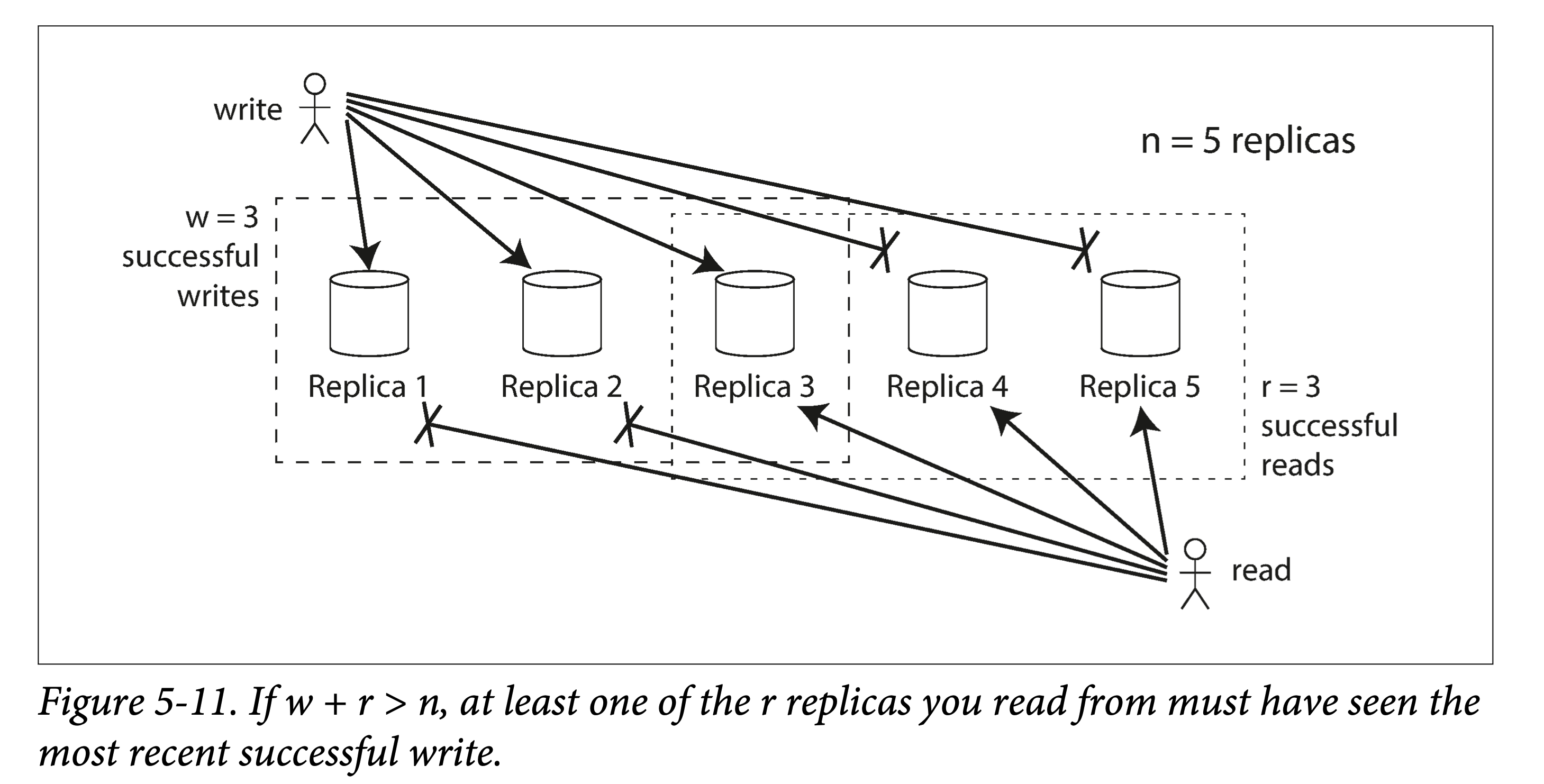 w+r>n
w+r>n
In Dynamo-style storage, n, r, and w are usually configurable:
- The larger n, the higher the redundancy and reliability.
- r and w are often both chosen to exceed half, such as
(n+1)/2. - When w = n, you can set r = 1. This sacrifices write performance for read performance.
Considering the tolerance to node failures of a system satisfying w + r > n:
- If w < n, writes can still proceed normally when some nodes are unavailable.
- If r < n, reads can still proceed normally when some nodes are unavailable.
Specializing:
- If n = 3, r = w = 2, the system can tolerate at most one node down.
- If n = 5, r = w = 3, the system can tolerate at most two nodes down.
Usually, we send reads or writes in parallel to all n replicas, but we can return as soon as we have quorum results.
If, for some reason, the number of available nodes is less than r or w, the read or write will fail.
Limitations of Quorum Consistency
When w + r > n, there will always be at least one node (the intersection of the read and write subsets) that holds the latest data, so we always expect to be able to read the latest.
When w + r ≤ n, it is very likely to read stale data.
But even when w + r > n, there are some corner cases that can cause the client to fail to read the latest data:
- When using a sloppy quorum (the set of n machines can change), w and r may not overlap.
- For concurrent writes, if conflicts are handled improperly. For example, using a last-write-wins strategy based on local timestamps may cause data loss due to clock skew.
- For concurrent reads and writes, if the write succeeds on only some nodes before being read, it is uncertain whether the new or old value should be returned.
- If the number of written nodes < w causing the write to fail, but the data is not rolled back, the client will still read old data when reading.
- Although the number of successful nodes during writing > w, some replicas crashed due to failures in between, causing the number of successful replicas < w, which may cause problems when reading.
- Even if everything works normally, there may be some timing-related corner cases.
Therefore, although quorum reads and writes seem to guarantee returning the latest value, in engineering practice, there are many details to handle.
If the database does not comply with the consistency guarantees introduced in the replication lag section above, the anomalies mentioned earlier may still occur.
Consistency Monitoring
Monitoring replica data staleness allows you to understand the health of replicas; when they lag too far behind, you can investigate the cause in time.
In leader-based multi-replica models, since each replica replicates in the same order, it is convenient to give the lag progress of each replica.
But for leaderless models, since there is no fixed write order, the lag progress of replicas becomes difficult to define. If the system only uses the read repair strategy, there is no limit to how far a replica can lag. Data with very low read frequency may have very old versions.
Eventual consistency is a very vague guarantee, but being able to quantify “eventually” through monitoring (e.g., to a threshold) is also great.
Sloppy Quorum and Hinted Handoff
A normal quorum can tolerate some replica node failures. But in large clusters (total node count > n), the initially chosen n machines may, for various reasons (crashes, network issues), fail to reach the quorum read or write count. At this point, there are two choices:
- Directly return errors for all reads and writes that cannot reach r or w quorum.
- Still accept writes, and temporarily hand the new writes to some normal nodes.
The latter is considered a sloppy quorum: reads and writes still require w and r successful responses, but the set of nodes involved can change.
 sloppy quorum
sloppy quorum
Once the problem is resolved, the data will be moved back to the nodes where it should be (D → B) based on hints; we call this hinted handoff. This handoff process is completed by the anti-entropy background process.
This is a typical practice of sacrificing some consistency for higher availability. In common Dynamo implementations, sloppy quorum is optional. In Riak, they are enabled by default; in Cassandra and Voldemort, they are disabled by default.
Multi-Data-Center
The leaderless model is also applicable to multi-data-center deployments.
To simultaneously accommodate multi-data-center and low write latency, there are different multi-data-center strategies based on the leaderless model:
- Cassandra and Voldemort configure n across all data centers, but when writing, they only wait for replicas in the local data center to complete before returning.
- Riak limits n within a single data center, so all client-to-storage-node communication can be limited to a single data center, while data replication is performed asynchronously in the background.
Detecting Concurrent Writes
Since Dynamo allows multiple clients to concurrently write the same key, even using strict quorum reads and writes, conflicts will arise: for two writes to the same key within a short time interval (concurrently), the order received on different replicas may be inconsistent.
In addition, conflicts may also arise during read repair and hinted handoff.
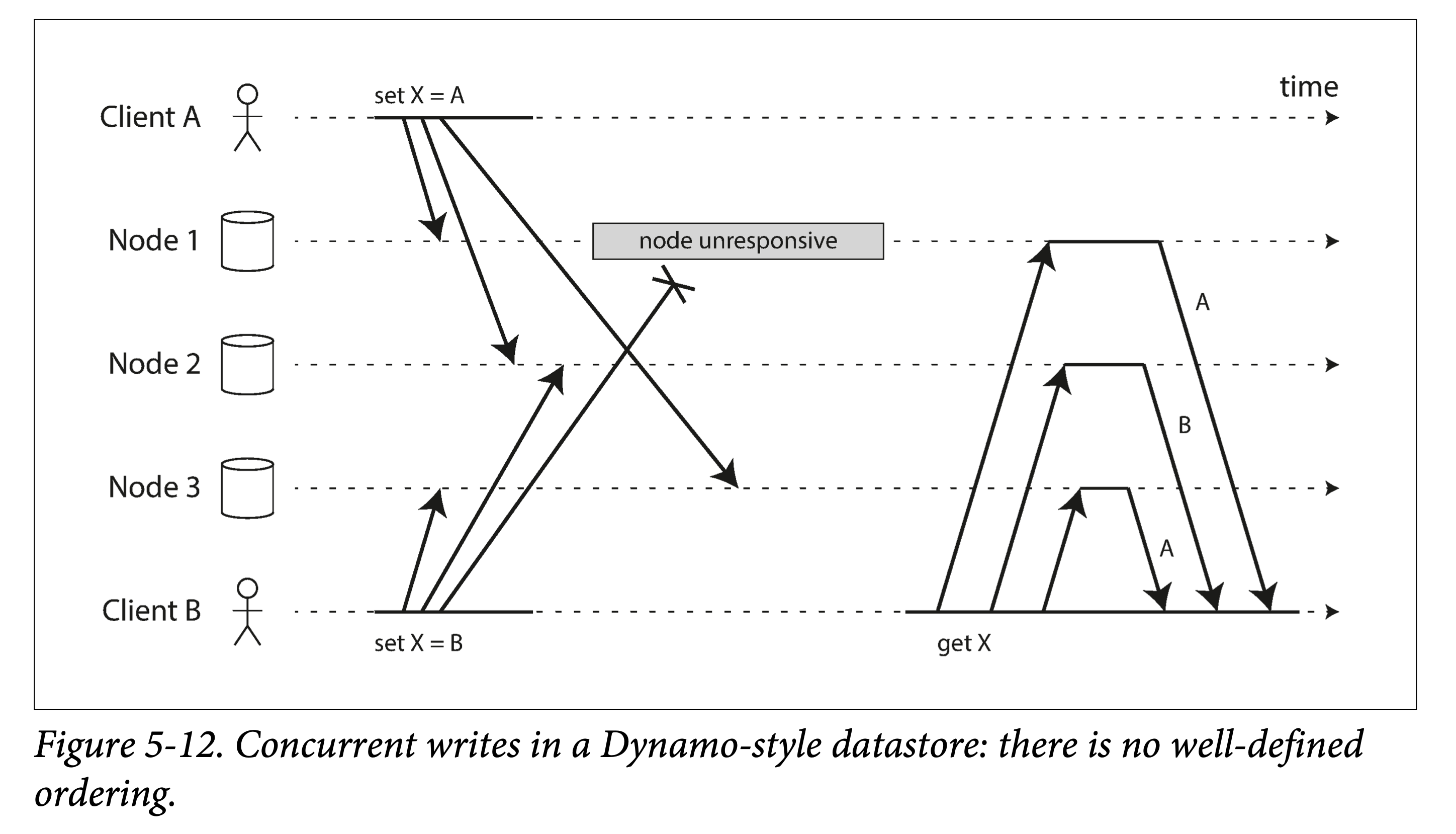 dynamo style datastore
dynamo style datastore
As shown in the figure above, if each node does not check the order but simply accepts the write request and stores it locally, permanent inconsistency may occur between different replicas: in the figure above, the value of replica X on Node1 and Node3 is A, while the value of replica X on Node2 is B.
To make all replicas eventually consistent, there needs to be a means to resolve concurrent conflicts.
Last-Write-Wins
The last-write-wins (LWW) strategy determines a globally unique order by some means, and then lets the later modification overwrite the earlier one.
For example, attach a global timestamp to all writes; if there is a conflict for a key, keep the data with the largest timestamp and discard earlier writes.
LWW has a problem: multiple concurrently writing clients may all think they succeeded, but in the end only one value is retained, and the others are silently discarded in the background. That is, upon immediately re-reading, they will find it is not the data they wrote.
The only safe way to use LWW is: the key is written once and then becomes read-only. For example, Cassandra recommends using a UUID as the primary key, so each write operation will have a unique key.
Happens-Before and Concurrency Relationships
Consider the two previous figures:
- In Figure 5-9, since client B’s update depends on client A’s insert, they have a causal relationship.
- In Figure 5-12, set X = A and set X = B are concurrent, because neither is aware of the other’s existence, and there is no causal relationship.
For any two writes A and B in the system, there are only three possible relationships:
- A happens before B
- B happens before A
- A and B are concurrent
From another perspective (set operations),
1 | A 和 B 并发 < === > A 不 happens-before B && B 不 happens-before A |
If two operations can be ordered, last write wins; if two operations are concurrent, conflict resolution is needed.
Concurrency, Time, and Relativity
Lamport clock related papers have detailed derivations of related conceptual relationships. To define concurrency, the absolute chronological order of events is not important; as long as two events are unaware of each other’s existence, the two operations are called “concurrent.” From the perspective of special relativity, as long as the time difference between two events is less than the time it takes light to travel between them, the two events cannot affect each other. Generalizing to computer networks, as long as due to network issues, within the time difference of the events, the two cannot become aware of each other, they are said to be concurrent.
Determining the Happens-Before Relationship
We can use some algorithm to determine whether any two events in the system have a happens-before relationship or are concurrent. Looking at an example of two clients concurrently adding items to a shopping cart:
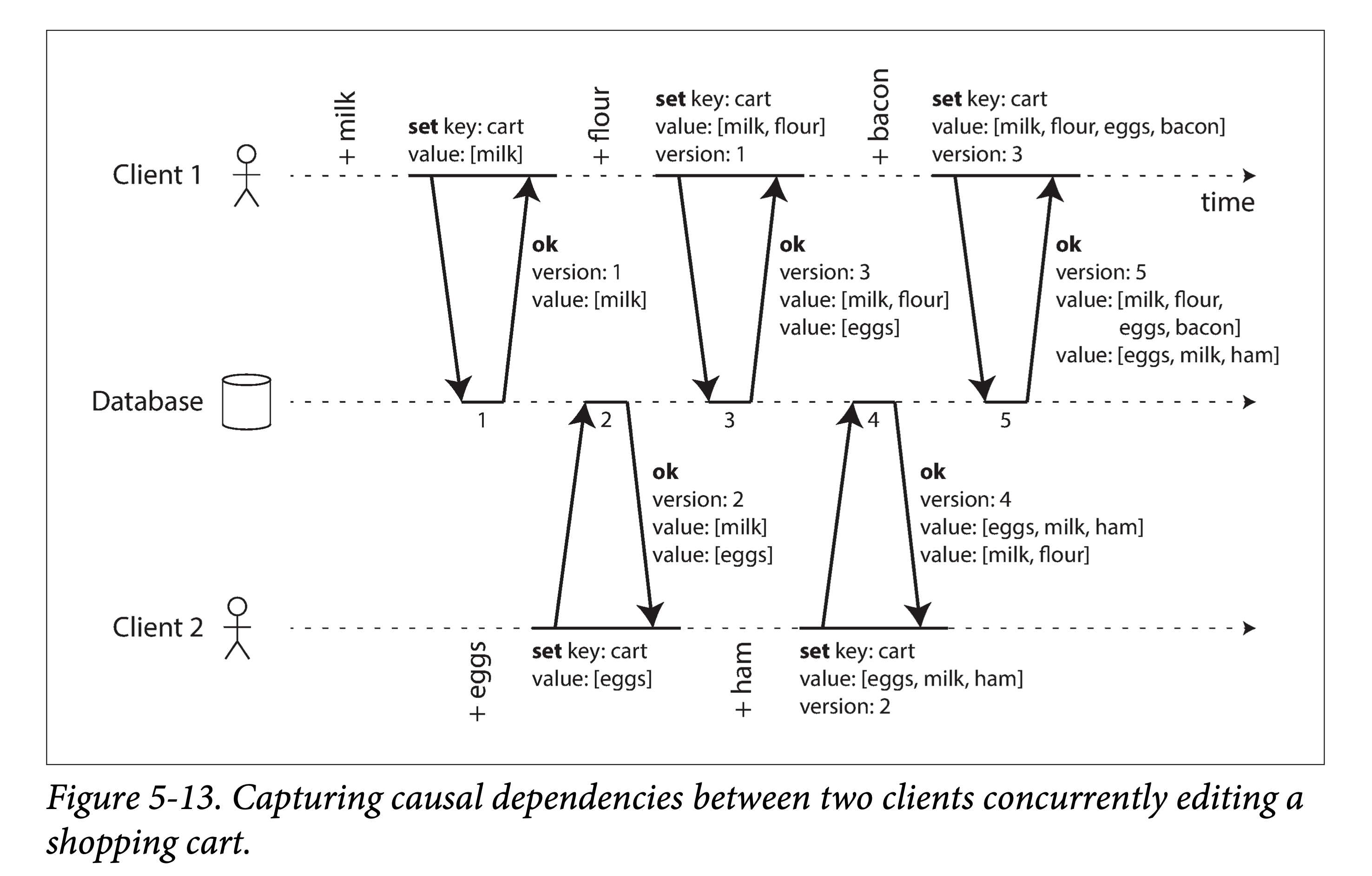 causal dependencies
causal dependencies
Note:
- No active reads; only active writes, reading the current database state through the return value of the write.
- The client’s next write depends on (causal relationship) the return value obtained after its own previous write.
- For concurrency, the database does not overwrite but preserves multiple concurrent values (one per client).
The data flow in the above figure is shown below. Arrows represent happens-before relationships. In this example, the client can never fully know the server data, because there is always another client performing concurrent operations. But old version values will be overwritten, and writes will not be lost.
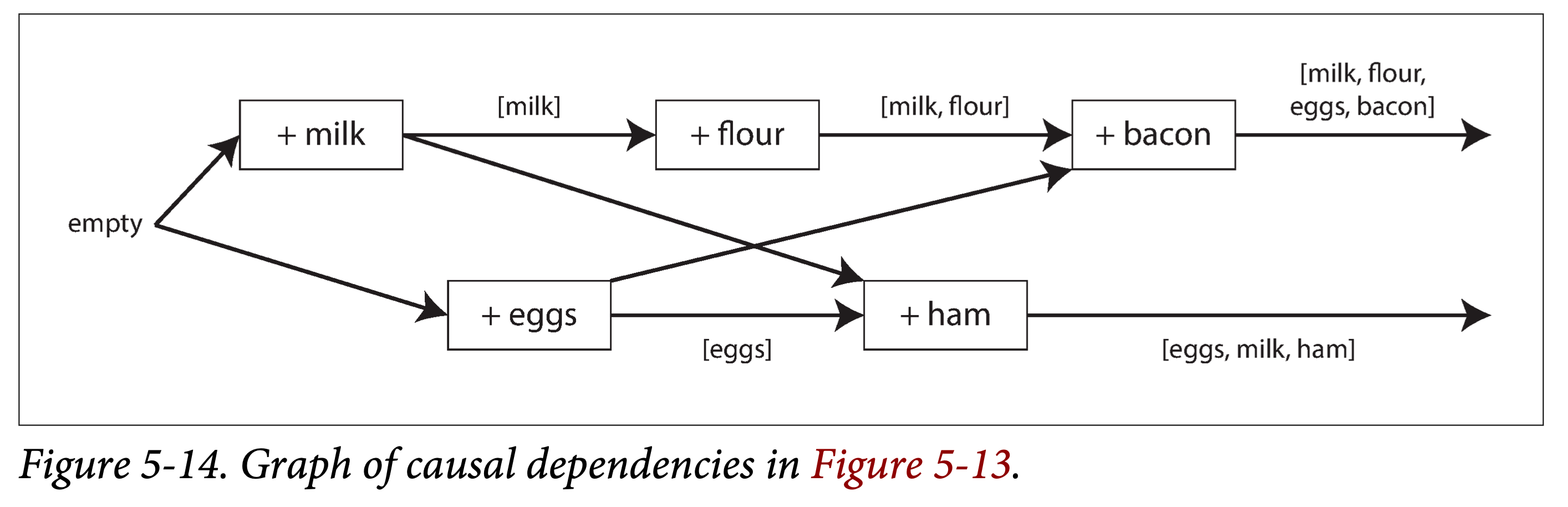 graph causal dependencies
graph causal dependencies
To summarize, the algorithm is as follows:
- The server assigns a version number V to each key; each time the key is written, V is incremented by 1, and the version number is saved together with the written value.
- When a client reads the key, the server returns all values that have not been overwritten and the latest version number.
- When the client performs the next write, it must include the version number Vx previously read (indicating which version the new write is based on), and merge all values read together.
- When the server receives a write with a specific version number Vx, it can use its value to overwrite all values with V ≤ Vx.
If a new write comes that is not based on any version number, this write will not overwrite anything.
Merging Concurrent Values
This algorithm can guarantee that no data is silently discarded. But clients need to merge previous values when writing later to clean up multiple values. If simply using LWW based on timestamps, some data will be lost again.
Therefore, strategies need to be chosen based on actual circumstances to resolve conflicts and merge data.
- For the shopping cart example above where only items are added, a “union” can be used to merge conflicting data.
- If there are also delete operations in the shopping cart, a simple union will not suffice; but deletion can be turned into an addition (writing a tombstone marker).
Version Vectors
The above example has only a single replica. When extending this algorithm to the leaderless multi-replica model, using a single version value is obviously insufficient; at this point, a version number needs to be introduced for each key on each replica. For the same key, versions from different replicas form a version vector.
1 | key1 |
Each replica increments the version number of the corresponding key when it encounters a write, while tracking the version numbers seen from other replicas; by comparing version numbers, it decides which values to overwrite and which to preserve.

