The DDIA Reading Group shares chapter by chapter, combining some of my experience in distributed storage and databases in the industry to supplement details. Sharing occurs approximately every two weeks; welcome to join. The schedule and all transcripts are here. We have a corresponding distributed systems & database discussion group; notifications will be sent in the group before each sharing session. If you would like to join, you can add my WeChat: qtmuniao, briefly introduce yourself, and note: Distributed Systems Group.
Chapter 3 discussed storage engines; this chapter continues to dig deeper, exploring encoding-related issues.
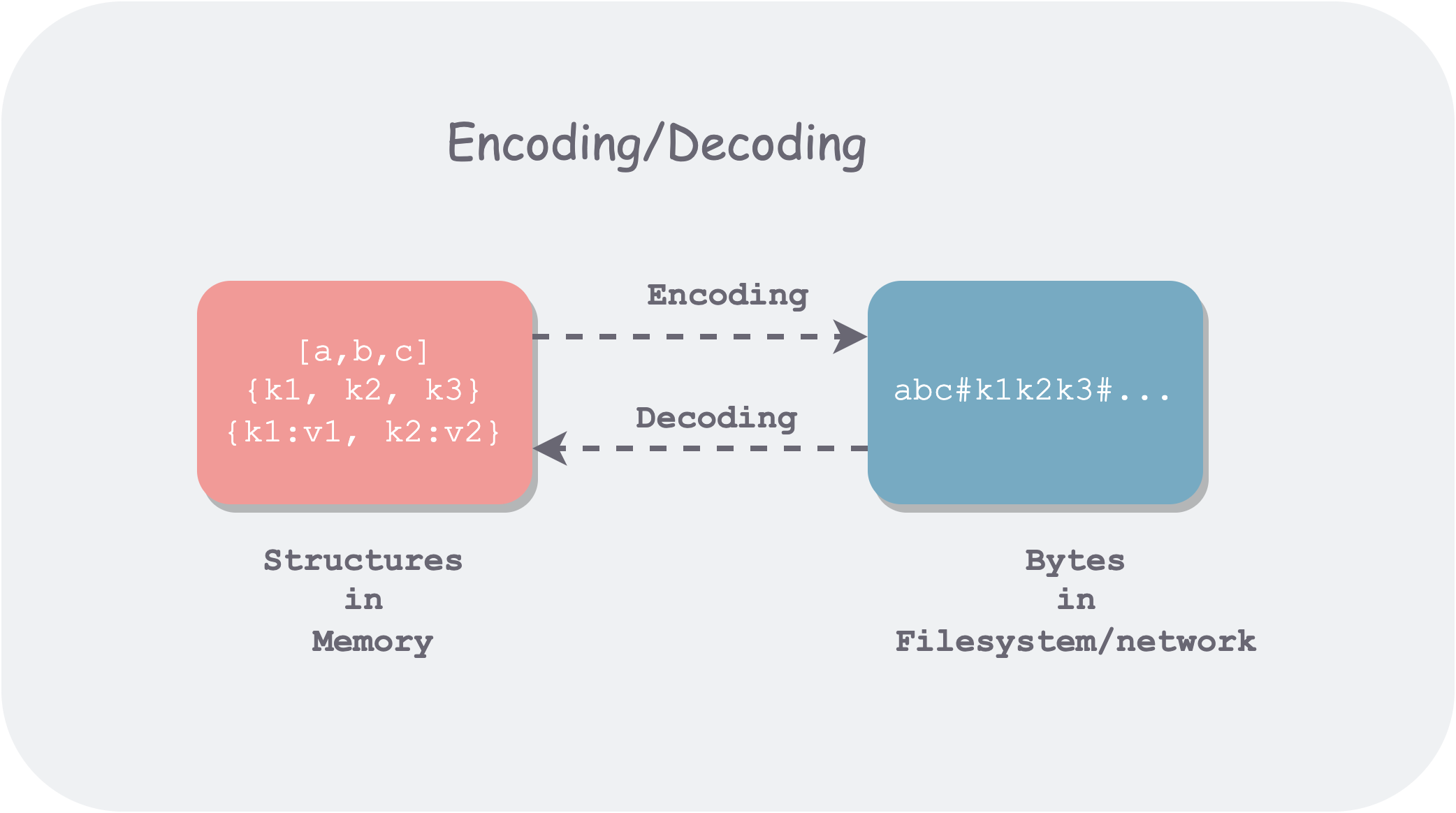
All places involving cross-process communication require data to be encoded (Encoding), or serialized (Serialization). Because persistent storage and network transmission are both byte-stream-oriented. Serialization is essentially a “dimensionality reduction” operation, reducing high-dimensional data structures in memory to a single-dimensional byte stream, so that underlying hardware and related protocols only need to handle one-dimensional information.
Author: Muniao Notes https://www.qtmuniao.com/2022/04/16/ddia-reading-chapter4 Please cite the source when reposting
Encoding mainly involves two aspects:
- How to encode to save space and improve performance.
- How to encode to accommodate data evolution and compatibility.
The first section takes several common encoding tools (JSON, XML, Protocol Buffers, and Avro) as examples, discussing one by one how they perform encoding and how to achieve multi-version compatibility. Here, two very important concepts are introduced:
- Backward compatibility: current code can read data written by older versions of the code.
- Forward compatibility: current code can read data written by newer versions of the code.
After translation into Chinese, these are easily confused, mainly due to the ambiguity of “后” (hòu)—does it mean behind (the past) or after (the future)? Personally, I think it would be better to translate them as compatible with the past and compatible with the future. But for the sake of convention, I will still use backward/forward compatibility in the following text.
Among them, backward compatibility is more common, because time always moves forward, versions always upgrade, and after upgrading, the code must always handle historical backlog data, naturally producing backward compatibility issues. Forward compatibility is relatively rare; the example given in the book is rolling upgrades across multiple instances, but even then the duration is very short.
The second section combines several specific application scenarios—databases, services, and messaging systems—to discuss the encoding and evolution involved in the relevant data flows.
Data Encoding Formats
 ddia4-encoding-decoding.png
ddia4-encoding-decoding.png
Encoding has many names, such as serialization or marshalling. Correspondingly, decoding also has many aliases: parsing, deserialization, unmarshalling.
-
Why is data in memory so different from data in external storage and on the network?
With the help of compilers, we can interpret memory as various data structures; but in file systems and networks, we can only stream-read byte streams through a few limited operations like seek/read. What about mmap?
-
Encoding and serialization colliding?
In transactions, there are also terms related to serialization, so here we specifically use “encoding” to avoid ambiguity.
-
Encoding and encryption?
The research scopes are somewhat different. Encoding is for persistence or transmission, focusing on format and evolution; whereas encryption is for security, focusing on safety and preventing cracking.
Language Built-ins
Many programming languages have built-in default encoding methods:
- Java has
java.io.Serializable - Ruby has
Marshal - Python has
pickle
If you are certain that your data will only be read by a specific language, then these built-in encoding methods work well. For example, deep learning researchers basically all use Python, so they often pass data around in pickle format.
But these programming language built-in encoding formats have the following disadvantages:
- Bound to a specific language
- Security issues
- Insufficient compatibility support
- Low efficiency
JSON, XML, and Their Binary Variants
JSON, XML, and CSV belong to commonly used text encoding formats. Their advantage is human readability; their disadvantage is that they are not compact enough and take up more space.
JSON was originally introduced by JavaScript, so it is used more in Web Services. Of course, with the popularity of the web, it has now become a relatively general encoding format—for example, many log formats are JSON.
XML is quite old and even more redundant than JSON. It is sometimes used in configuration files, but overall it is being used less and less.
CSV (delimited by commas, TABs, and newlines) is fairly compact, but its expressiveness is limited. It is sometimes used for database table exports.
In addition to not being compact enough, text encoding has the following disadvantages:
- Insufficient support for numeric types. CSV and XML simply do not support them—everything is a string. Although JSON distinguishes between strings and numbers, it does not further distinguish between subtypes of numeric types. This is understandable; after all, text encoding is mainly string-oriented.
- Insufficient support for binary data. It supports Unicode but not binary strings well, which may display as garbled text. Although this can be bypassed via Base64 encoding, it feels somewhat like doing useless work.
- XML and JSON support additional schemas. A schema describes the data types and tells you how to understand the data. Cooperating with these schema languages can make XML and JSON powerful, but greatly increases complexity.
- CSV has no schema at all.
Everything is about being good enough. In many scenarios, data readability is required and encoding efficiency is not a concern, so these encoding formats are sufficient.
Binary Encoding
If data is only read by a single program, does not need to be exchanged, and readability is not a concern, then binary encoding can be used. After the data volume reaches a certain level, the space savings and speed improvements brought by binary encoding are considerable.
Therefore, JSON has many binary variants: MessagePack, BSON, BJSON, UBJSON, BISON, and Smile, etc.
For the following example,
1 | { |
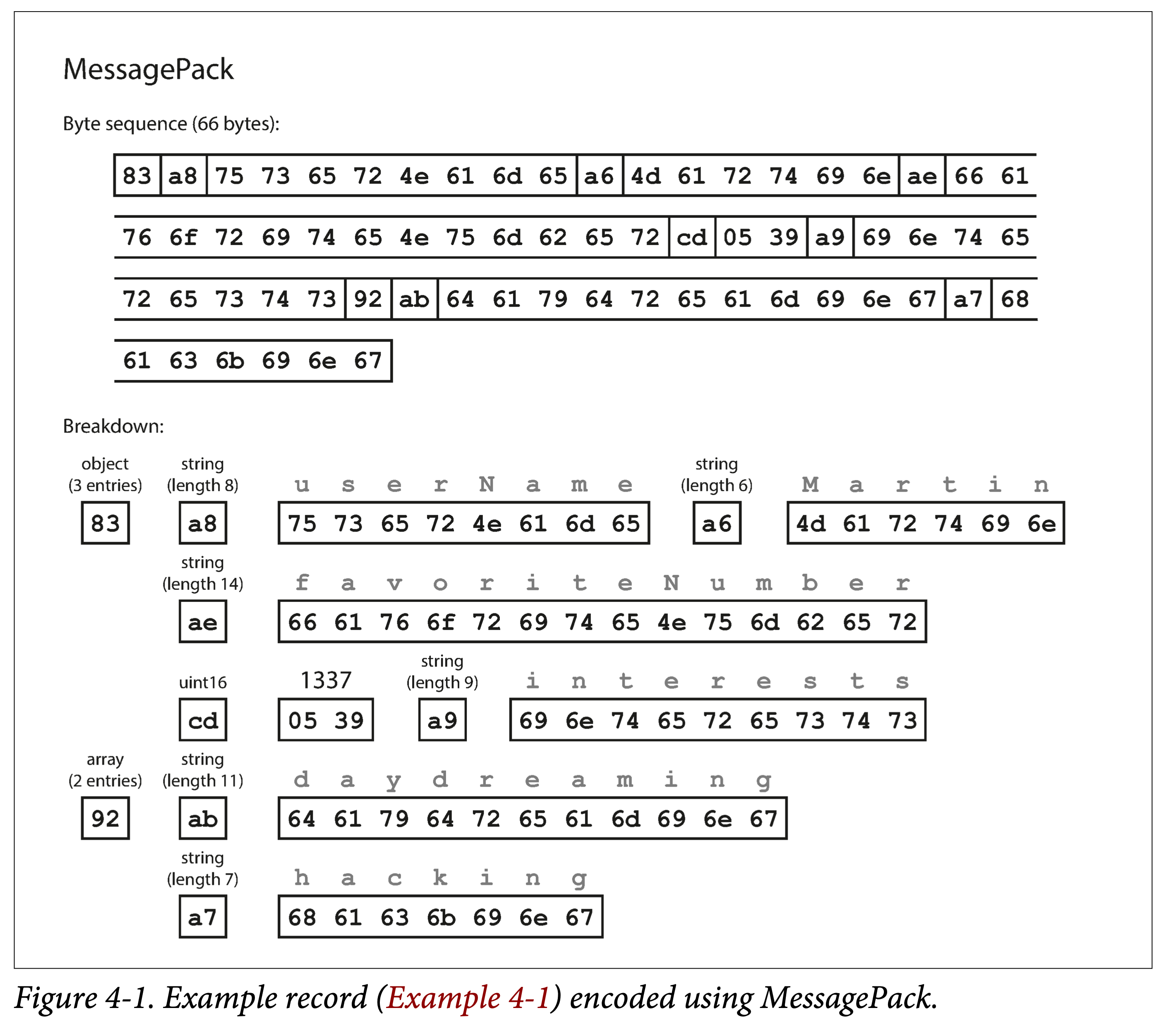
If encoded using MessagePack, it becomes:
 ddia-4-messagepack-enc.png
ddia-4-messagepack-enc.png
It can be seen that the basic encoding strategy is: encode in the order of type, length, bit string, removing useless colons, quotation marks, and curly braces.
Thus, the 81 bytes of JSON encoding are reduced to 66 bytes, a slight improvement.
Thrift and Protocol Buffers
Thrift was originally open-sourced by Facebook, and ProtoBuf by Google around 2007–2008. Both have corresponding RPC frameworks and encoding/decoding tools. Their expressiveness is similar, and their syntax is similar; before encoding, both need to describe the schema using an Interface Definition Language (IDL):
1 | struct Person { |
1 | message Person { |
IDL is programming-language-agnostic. Using relevant code generation tools, the above IDL can be translated into code for a specified language. That is, by integrating this generated code, no matter what language is used, the same format can be used for encoding and decoding.
This is also the foundation that allows different services to use different programming languages and still communicate with each other.
In addition, Thrift supports multiple different encoding formats, commonly used ones being: Binary, Compact, and JSON. This allows users to make their own trade-offs among encoding speed, space usage, and readability.
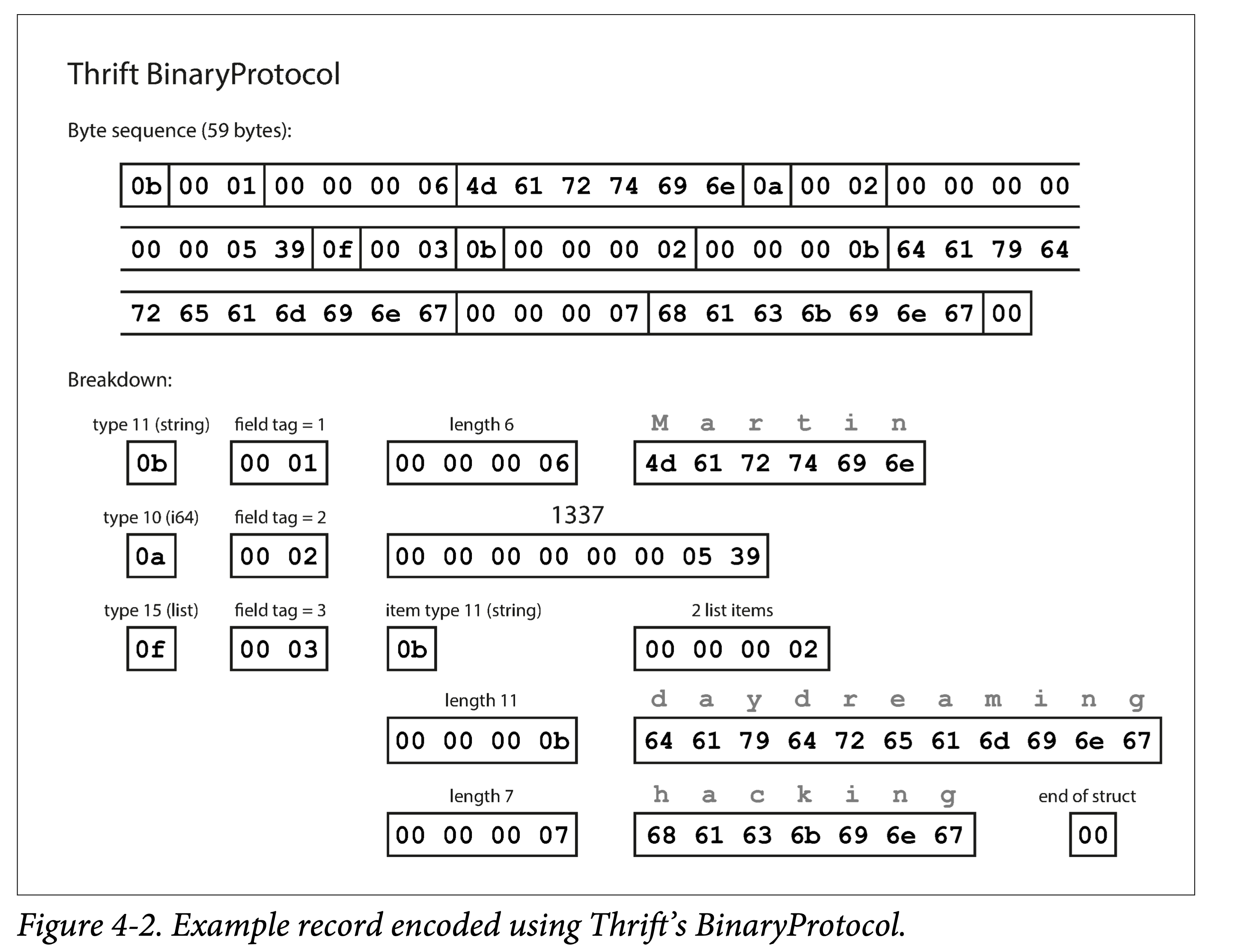 ddia4-thrift-binary-enc.png
ddia4-thrift-binary-enc.png
Its characteristics can be seen:
- Encoding using field tags. A field tag actually implies the field type and name.
- Encoding in the order of type, tag, length, and bit array.
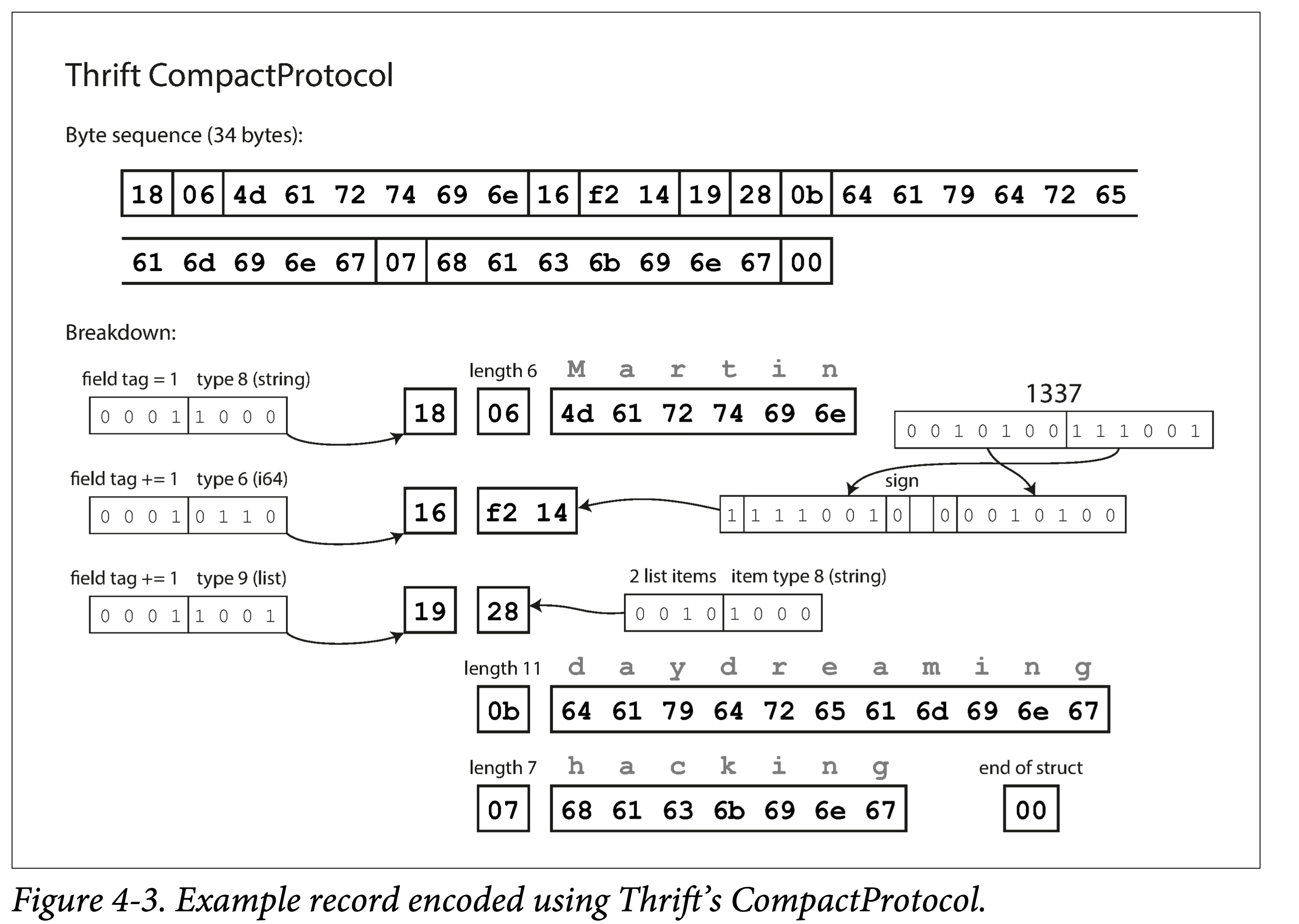 ddia4-thrift-compact-enc.png
ddia4-thrift-compact-enc.png
Compared to Binary Protocol, Compact Protocol has the following optimizations:
- The field tag only records the delta.
- Thus compressing the field tag and type into one byte.
- Using variable-length encoding and Zigzag encoding for numbers.
ProtoBuf is very similar to Thrift Compact Protocol in encoding, also using variable-length encoding and Zigzag encoding. But ProtoBuf’s handling of arrays is significantly different from Thrift’s, using a repeated prefix rather than a true array—the benefits of which will be discussed later.
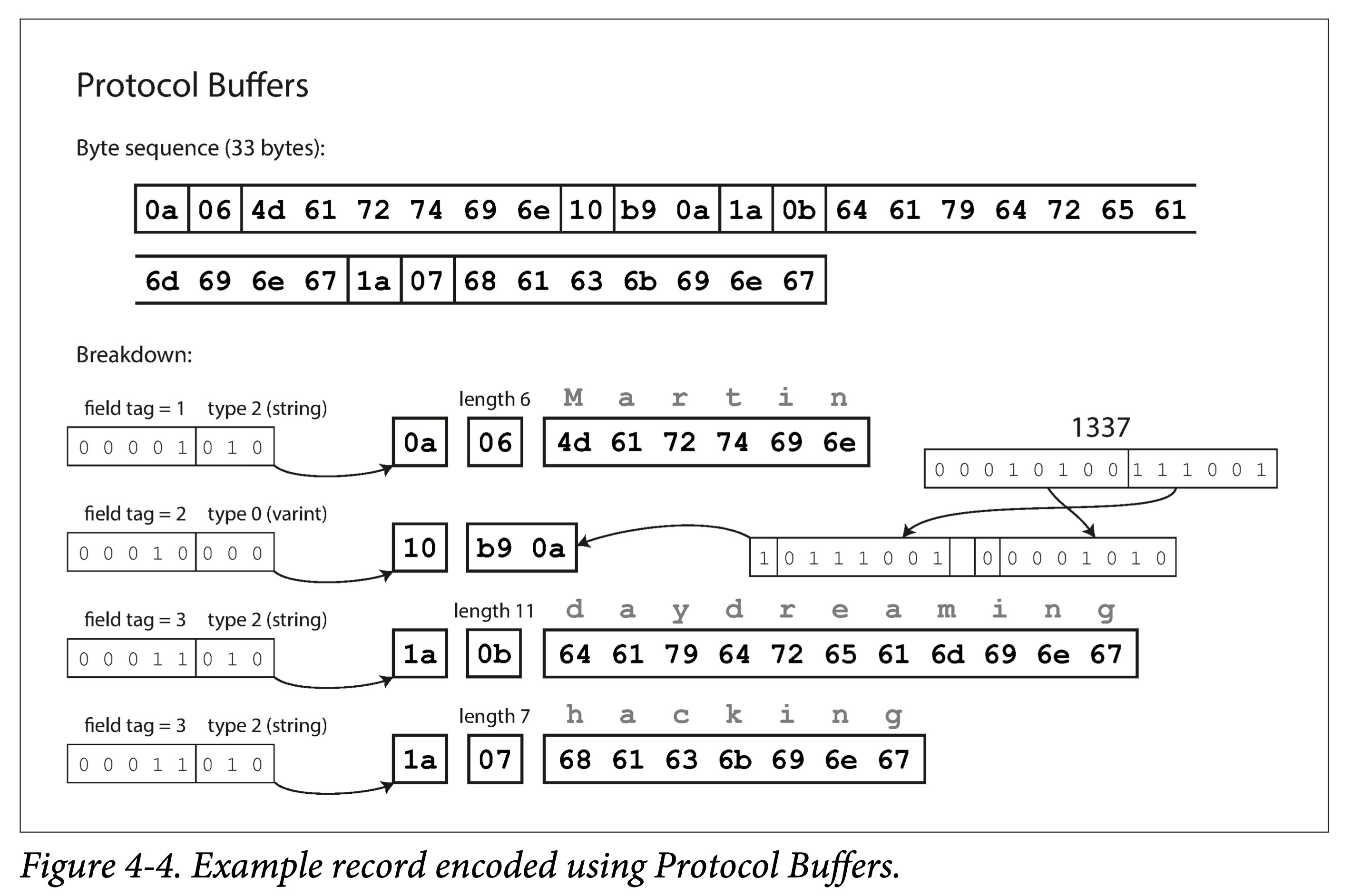 ddia4-pb-enc.png
ddia4-pb-enc.png
Field Tags and Schema Evolution
Schema, that is, what fields there are and what type each field is.
As time goes by, business always changes, and we inevitably add or delete fields, modify field types—that is, schema evolution.
After the schema changes, we need:
- Backward compatibility: new code, while processing new incremental data formats, must also handle old stock data.
- Forward compatibility: old code, if it encounters new data formats, must not crash.
-
How do ProtoBuf and Thrift solve these two problems?
Field tags + qualifiers (optional, required)
Backward compatibility: newly added fields must be optional. This way, when parsing old data, there will be no missing field situation.
Forward compatibility: field tags cannot be modified, only appended. This way, when old code sees an unrecognized tag, it can simply skip it.
Data Types and Schema Evolution
Modifying data types is quite troublesome: modifications can only be made among compatible types.
For example, a string cannot be changed to an integer, but modifications within integers are allowed: 32-bit to 64-bit integers.
ProtoBuf does not have a list type, but rather a repeated type. Its benefit is that while being compatible with array types, it supports modifying an optional single-value field to a multi-value field. After modification, when old code sees the new multi-value field, it will only use the last element.
Although Thrift’s list type does not have this flexibility, it can be nested.
Avro
Apache Avro is a subproject of Apache Hadoop, specifically designed for data-intensive scenarios, with good support for schema evolution. It supports two schema languages: Avro IDL and JSON; the former is suitable for manual editing, and the latter is suitable for machine reading.
1 | record Person { |
1 | { |
It can be seen that Avro does not use field tags.
-
Still encoding the previous example, Avro only uses 32 bytes. Why?
It does not encode the types.
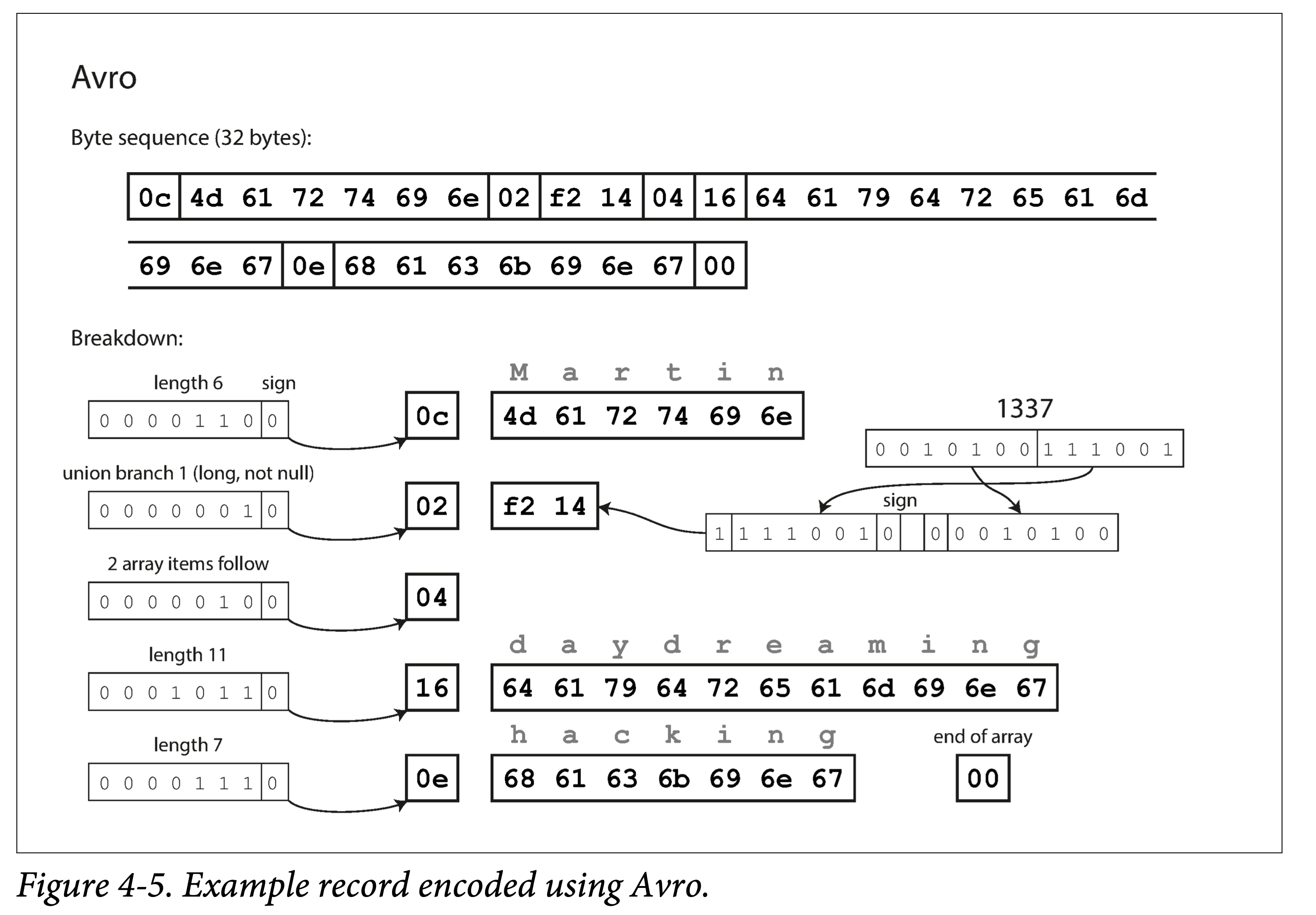 ddia4-avro-enc.png
ddia4-avro-enc.png
Therefore, Avro must work with a schema definition to parse, such as Client-Server exchanging data schemas during the handshake phase of communication.
Writer Schema and Reader Schema
-
Without field tags, how does Avro support schema evolution?
The answer is to explicitly use two schemas.
That is, when encoding data (writing to a file or transmitting), use schema A, called the writer schema; when decoding data (reading from a file or the network), use schema B, called the reader schema; and the two do not need to be identical, only compatible.
In other words, as long as the schemas are compatible during evolution, Avro can handle both backward and forward compatibility.
Backward compatibility: new code reads old data. That is, when reading, the writer schema of the old data (i.e., the old schema) is first obtained, then compared with the reader schema (i.e., the new schema) to obtain a transformation mapping, which is then used to parse the old data.
Forward compatibility: old code reads new data. The principle is similar, except that a reverse mapping needs to be obtained.
When establishing the mapping from the writer schema to the reader schema, there are some rules:
- Match using field names. Therefore, the field name order in the writer schema and reader schema does not matter.
- Ignore extra fields.
- Fill in default values for missing fields.
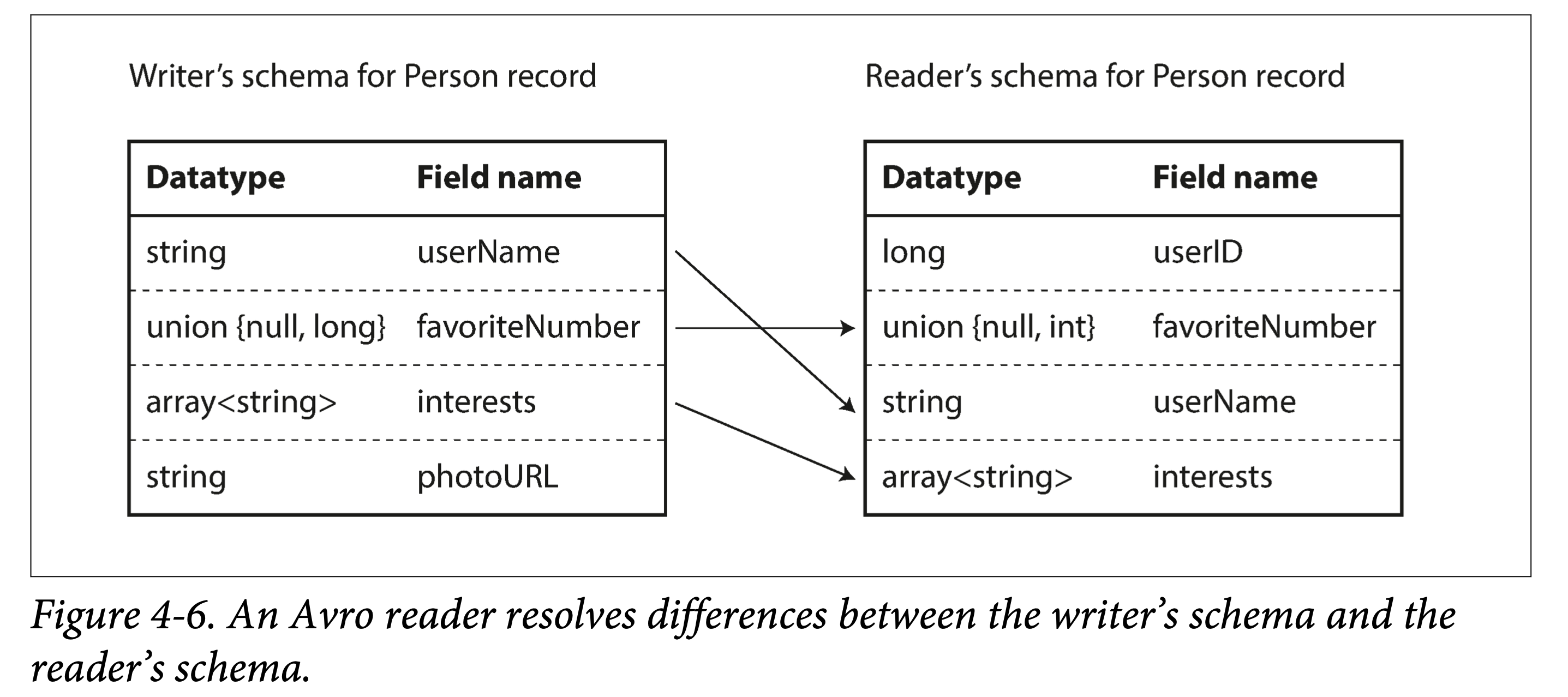 ddia-4avro-map.png
ddia-4avro-map.png
Schema Evolution Rules
- So how to ensure the compatibility of the writer schema?
- When adding or deleting fields, you can only add or delete fields that have default values.
- When changing a field type, Avro needs to support the corresponding type conversion.
Avro does not have optional and required qualifiers like ProtoBuf and Thrift; instead, it uses a union to specify default values and even multiple types:
1 | union {null, long, string} field; |
Note: The default value must be of the type of the first branch of the union.
Changing a field name and adding a type to a union are both backward compatible, but not forward compatible. Think about why?
How to Obtain the Writer Schema from Encoded Data
For a given piece of Avro-encoded data, how does the Reader obtain its corresponding writer schema?
This depends on different application scenarios.
-
Large files where all data entries are homogeneous
Typical of the Hadoop ecosystem. If all records in a large file are encoded using the same schema, then the writer schema only needs to be included once in the file header.
-
Database tables that support schema changes
Since database tables allow schema modifications, the rows in them may have been written during different schema stages. For this situation, an extra schema version number (e.g., auto-incrementing) can be recorded at encoding time, and all schema versions can be stored somewhere.
When decoding, the corresponding writer schema can be queried by version.
-
Sending data over the network
During the handshake phase of communication between two processes, exchange the writer schemas. For example, exchange schemas at the beginning of a session, and then use this schema throughout the session lifecycle.
Schemas in Dynamically Generated Data
One advantage of Avro not using field tags is that there is no need to manually maintain the mapping from field tags to field names, which is friendly for dynamically generated data schemas.
The example given in the book is exporting backups from a database—note that this is different from the database itself using Avro encoding; here it refers to the exported data being encoded using Avro.
Before and after changes to the database table schema, Avro only needs to perform corresponding conversions based on the schema at the time of export and generate the corresponding schema data. But if PB were used, you would need to handle the mapping from field tags to field names across multiple backup files yourself. The essence is that Avro’s data schema can coexist with the data, whereas ProtoBuf’s data schema can only be reflected in the generated code and requires manual maintenance of the mapping between old and new versions of backup data and the PB-generated code.
Code Generation and Dynamic Languages
Thrift and Protobuf generate encoding/decoding code for a given language based on the language-agnostic IDL-defined schema. This is very useful for static languages, because it allows using IDEs and compilers for type checking and can improve encoding/decoding efficiency.
The essence of the above approach is to internalize the schema into the generated code.
But for dynamic languages, or interpreted languages, such as JavaScript, Ruby, or Python, since there is no compile-time check, the significance of generated code is not as great, and it actually introduces some redundancy. At this time, frameworks like Avro that support not generating code save some effort; it can write the schema into the data file, and use Avro for dynamic parsing when reading.
Advantages of Schemas
The essence of a schema is explicit type constraints—that is, there must be a schema before there can be data.
Compared to text encodings like JSON, XML, and CSV that have no type constraints, binary encodings based on explicit definitions like Protocol Buffers, Thrift, and Avro have the following advantages:
- Omit field names, making them more compact.
- The schema is an annotation or documentation of the data, and is always up-to-date.
- The data schema allows low-cost compatibility checks by comparing schemas only, without reading the data.
- For static types, code generation can be used for compile-time type checking.
Schema Evolution vs. Schema on Read
Several Data Flow Models
Data can flow from one system to another in many forms, but what remains unchanged is that encoding and decoding are always required during flow.
When data flows, there will be schema matching issues between the encoding and decoding parties; the previous subsection has already discussed this. This subsection mainly explores several typical inter-process data flow methods:
- Through databases
- Through service calls
- Through asynchronous message passing
Data Flow Through Databases
Programs accessing databases may:
- Be accessed by only the same process. Then the database can be understood as an intermediary through which the process sends data to the future.
- Be accessed by multiple processes. Then some processes may be old versions and some new versions; at this time, the database needs to consider forward and backward compatibility issues.
There is also a rather tricky situation: at some point, you add a field to a table; newer code writes rows with that field, and then older code overwrites them into rows missing that field. At this point, a problem arises: we updated a field A, and after the update, we find that field B is gone.
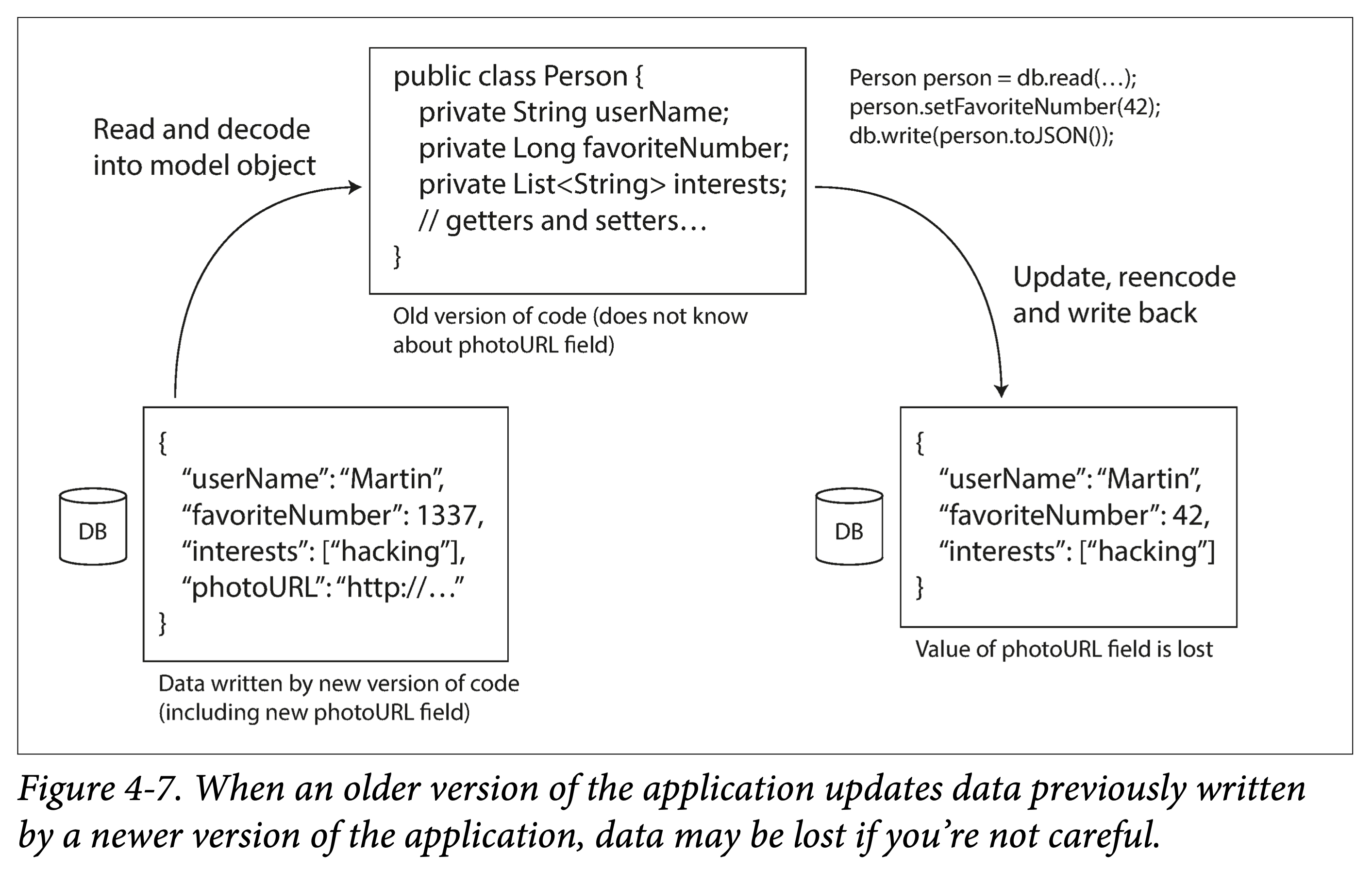 ddia-4-update-by-old.png
ddia-4-update-by-old.png
Data Written at Different Times
For applications, it may take only a short time to replace the old version with the new version. But for data, the amount of data written by old versions of code may be very large, accumulated over years. After changing the schema, because this old-schema data volume is very large, the cost of fully updating and aligning it to the new version is very high.
We call this situation: the lifetime of the data exceeds the lifetime of its corresponding code.
When reading, databases generally handle old data missing the corresponding column by:
- Filling in the default value for the new version field
- If there is no default value, filling in null (nullable)
Then returning it to the user. Generally, when changing the schema (e.g., alter table), the database does not allow adding columns that have neither a default value nor allow null.
Storage Archiving
Sometimes it is necessary to back up a database to external storage. When making a backup (or snapshot), although there may be data generated at different points in time, various versions of data are usually transformed and aligned to the latest version. After all, since you are doing a full data copy anyway, you might as well do the conversion at the same time.
As mentioned before, for this scenario, what is generated is one-time immutable backup or snapshot data, so using Avro is more appropriate. This is also a good opportunity to output data in the desired format, such as column-oriented storage formats for analytics: Parquet.
Data Flow Through Services: REST and RPC
When communicating over a network, there are usually two roles involved: server and client.
Generally speaking, services exposed to the public internet are mostly HTTP services, while RPC services are often used internally.
A server can also be a client at the same time:
- As a client accessing a database.
- As a client accessing other services.
The latter is because we often split a large service into a set of functionally independent, relatively decoupled services—this is service-oriented architecture (SOA), or the more recently popular microservices architecture. There are some differences between the two, but they will not be elaborated on here.
Services are somewhat similar to databases in that they allow clients to store and query data in some way. But the difference is that databases usually provide some flexible query language, whereas services can only provide relatively rigid APIs.
Web Services
When a service uses HTTP as its communication protocol, we usually call it a web service. But it is not limited to the web; it also includes:
- User terminals (such as mobile terminals) making requests to servers via HTTP.
- A service within the same organization sending HTTP requests to another service (microservices architecture, some of whose components are sometimes called middleware).
- Data exchange between services of different organizations. This generally requires some means of verification, such as OAuth.
There are two methods for designing HTTP APIs: REST and SOAP.
- REST is not a protocol, but a design philosophy. It emphasizes simple API formats, using URLs to identify resources and HTTP actions (GET, POST, PUT, DELETE) to perform CRUD operations on resources. Due to its concise style, it is becoming increasingly popular.
- SOAP is an XML-based protocol. Although it uses HTTP, its purpose is to be independent of HTTP. It is mentioned less frequently now.
Problems Faced by RPC
RPC wants to make calling remote services as natural as calling local (same-process) functions. Although the idea is good and it is now widely used, there are also some problems:
- A local function call either succeeds or fails. But RPC, because it goes through the network, may encounter various complex situations, such as lost requests, lost responses, hanging until timeout, etc. Therefore, retries may be needed.
- If retrying, the idempotency issue needs to be considered. Because the previous request may have already reached the server, but the response did not return successfully. Then multiple calls to the remote function must ensure that no additional side effects are caused.
- Remote call latency is unpredictable and greatly affected by the network.
- The programming languages used by the client and server may be different, but if some types are not available in both languages, there will be problems.
The advantage of REST over RPC is that it does not try to hide the network; it is more explicit, making it less easy for users to overlook the impact of the network.
Current Directions of RPC
Despite the above problems, in engineering, most of the time these situations are within tolerable ranges:
- For example, local area network networks are usually fast and controllable.
- For multiple calls, idempotency is used to solve the problem.
- For cross-language issues, RPC framework IDLs can be used to solve them.
But RPC programs need to consider the extreme cases mentioned above; otherwise, they may occasionally produce a very difficult-to-predict BUG.
In addition, RPC based on binary encoding is usually more efficient than HTTP-based services. But HTTP services, or more specifically, RESTful APIs, have the advantage of a good ecosystem and a large number of tool supports. RPC APIs are usually highly related to code generated by the RPC framework, so they are difficult to exchange and upgrade painlessly across different organizations.
Therefore, as stated at the beginning of this section: services exposed to the public internet are mostly HTTP services, while RPC services are often used internally.
Data Encoding and Evolution of RPC
Data flow through services can usually assume: all servers are updated first, and then clients are updated. Therefore, only backward compatibility needs to be considered in requests, and forward compatibility in responses:
- Thrift, gRPC (Protobuf), and Avro RPC can evolve according to the compatibility rules of their encoding formats.
- RESTful APIs usually use JSON as the request/response format; JSON is relatively easy to add new fields for evolution and compatibility.
- SOAP will not be discussed.
For RPC, service compatibility is relatively difficult because once the RPC service’s SDK is released, you cannot control its lifecycle: there will always be users who, for various reasons, will not actively upgrade. Therefore, it may be necessary to maintain compatibility for a long time, or give advance notice and keep announcing, or maintain multiple versions of the SDK and gradually phase out earlier versions.
For RESTful APIs, a common compatibility method is to put the version number in the URL or in the HTTP request header.
Data Flow via Message Passing
Earlier we studied different encoding/decoding methods:
- Database: one process writes (encodes), and a process in the future reads (decodes)
- RPC and REST: one process sends a request over the network (encoded before sending) to another process (decoded after receiving) and synchronously waits for a response.
This section studies asynchronous messaging systems that lie between databases and RPC: one storage (message broker, message queue for temporary message storage) + two RPCs (one for the producer, one for the consumer).
Compared to RPC, the advantages of using message queues are:
- If the consumer is temporarily unavailable, they can act as a temporary storage system.
- When the consumer crashes and restarts, messages are automatically resent.
- The producer does not need to know the consumer’s IP and port.
- A single message can be sent to multiple consumers.
- Producers and consumers are decoupled.
Message Queues
The book uses Message Broker, but another name, message queue, may be more familiar to everyone; therefore, the following text will use message queue.
In the past, message queues were monopolized by large companies. But in recent years, more and more open-source message queues have emerged to adapt to different scenarios, such as RabbitMQ, ActiveMQ, HornetQ, NATS, and Apache Kafka, etc.
The delivery guarantees of message queues vary by implementation and configuration, including:
- At-least-once: the same piece of data may be delivered to the consumer multiple times.
- At-most-once: the same piece of data will be delivered to the consumer at most once, and may be lost.
- Exactly-once: the same piece of data is guaranteed to be delivered to the consumer once and at most once.
The logical abstraction of a message queue is called a Queue or Topic; commonly used consumption methods are of two types:
- Multiple consumers mutually exclusively consume one Topic
- Each consumer exclusively consumes one Topic
Note: We sometimes distinguish these two concepts: calling point-to-point mutual consumption a Queue, and many-to-many publish-subscribe a Topic, but this is not universal, or rather, has not formed a consensus.
A Topic provides a unidirectional data flow, but multiple Topics can be combined to form complex data flow topologies.
Message queues are usually byte-array-oriented, so you can encode messages in any format. If the encoding is forward and backward compatible, the message format of the same topic can be flexibly evolved.
Distributed Actor Frameworks
The Actor model is a concurrent programming model based on message passing. An Actor is usually composed of three parts: State, Behavior, and Mailbox (which can be considered a message queue):
- State: the state information contained in the Actor.
- Behavior: the computation logic of the Actor on the state.
- Mailbox: the buffer where the Actor receives messages.
Because Actors interact with the outside world only through messages, they are inherently parallel and do not require locks.
Distributed Actor frameworks essentially integrate message queues and the Actor programming model together. Naturally, when rolling upgrading Actors, forward and backward compatibility issues also need to be considered.

