Overview
First, let me explain what BLOB means. Its full English name is Binary Large OBjects, which can be understood as large objects in arbitrary binary format; in Facebook’s context, these are images, videos, and documents uploaded by users. This data has the characteristics of created once, read many times, never modified, and occasionally deleted.
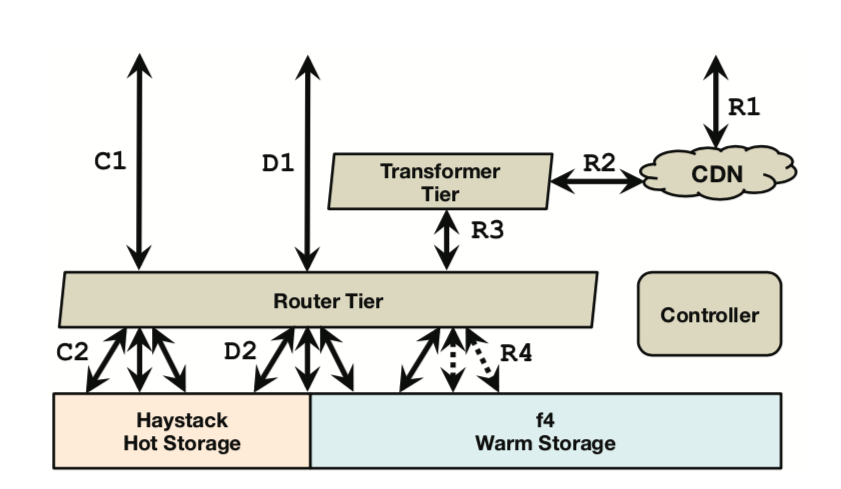
Previously, I briefly translated Facebook’s predecessor work — Haystack. As the business grew and data volume increased further, the old approach no longer worked. If all BLOBs were stored using Haystack, due to its triple-replication implementation, the cost-effectiveness at this scale would be very low. However, completely using network mounts + traditional disks + Unix-like (POSIX) file systems for cold storage couldn’t keep up with reads. Thus, the divide and conquer approach, most commonly used in computer science, came into play.
They first counted the relationship between BLOB access frequency and creation time, then proposed the concept of hot and cold distribution in BLOB access over time (similar to the long-tail effect). Based on this, they proposed a hot/warm separation strategy: using Haystack as hot storage to handle frequently accessed traffic, and using F4 to handle the remaining less frequently accessed BLOB traffic. Under this assumption (F4 only stores data that basically doesn’t change much and has relatively low access volume), F4’s design can be greatly simplified. Of course, there is a dedicated routing layer above both to shield the underlying details, make decisions, and route requests.
For Haystack, seven years had passed since its paper was published (07~14). Relative to that time, a few minor updates were made, such as removing the Flag bit, and adding a journal file in addition to the data file and index file, specifically to record deleted BLOB entries.
For F4, the main design goal is to minimize the effective replication factor (effective-replication-factor) as much as possible while ensuring fault tolerance, to address the growing demand for warm data storage. Furthermore, it is more modular and has better scalability, meaning it can smoothly scale by adding machines to cope with continuous data growth.
To summarize, the main highlights of this paper are hot/warm separation, erasure coding, and geo-replication.