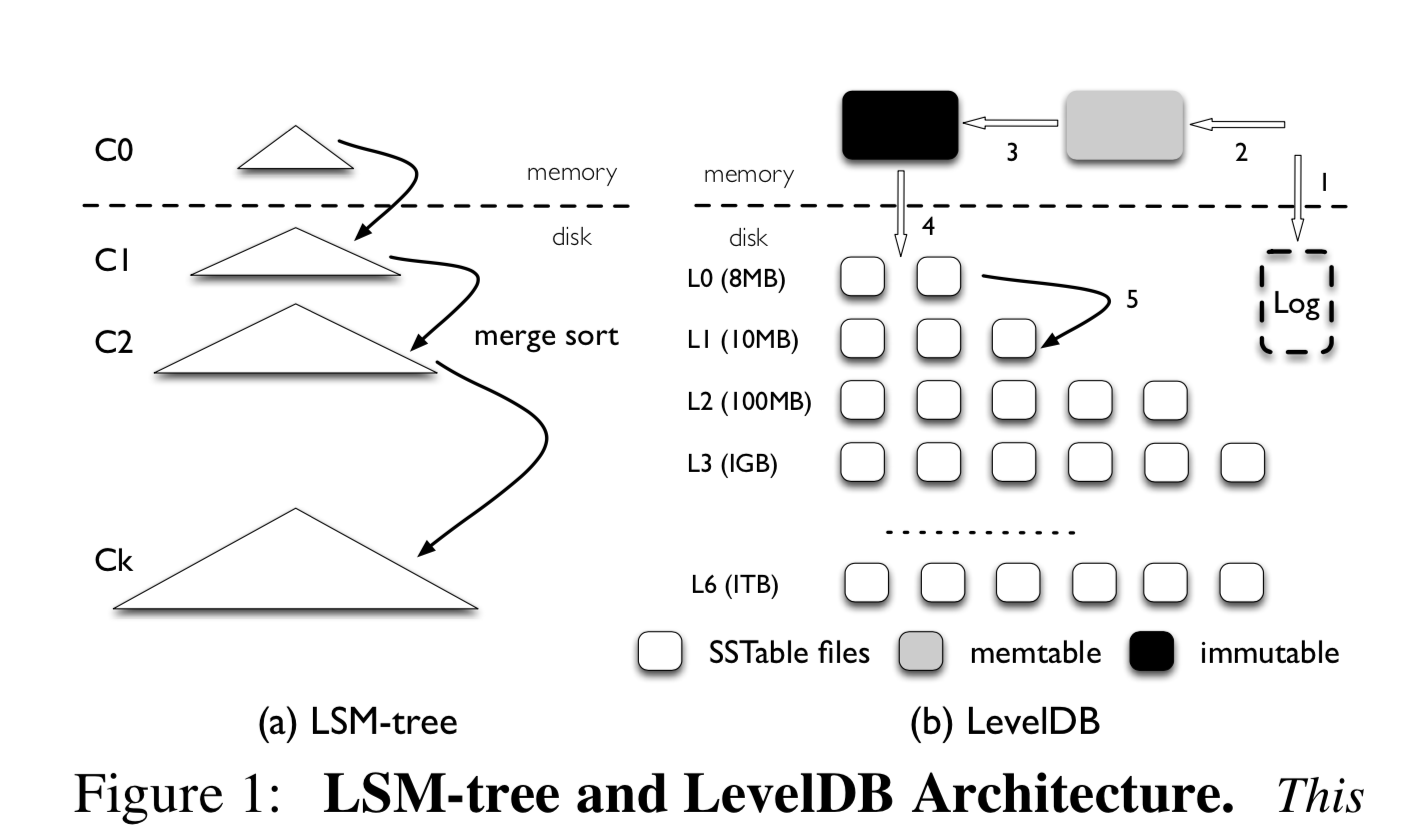
Overview
Dynamo is a highly available KV storage system. To ensure high availability and high performance, Dynamo adopts an eventual consistency model, providing developers with a novel API that uses versioning and resolves conflicts with client-side assistance. Dynamo aims to provide uninterrupted service while guaranteeing performance and scalability. Since Amazon widely adopts a decentralized, highly decoupled microservices architecture, the availability requirements for the storage system underlying these microservices are particularly high.
S3 (Simple Storage Service) is another well-known storage service from Amazon. Although it can also be understood as a KV store, its target scenario differs from that of Dynamo. S3 is an object storage service for large files, mainly storing binary files and not providing cross-object transactions. Dynamo, on the other hand, is a document storage service for small files, mainly storing structured data (such as JSON). It allows indexing data and supports transactions across data items.
Compared to traditional relational databases, Dynamo can be seen as providing only a primary key index, thereby achieving higher performance and better scalability.
To achieve scalability and high availability while ensuring eventual consistency, Dynamo combines the following techniques:
- Consistent hashing for data partitioning and replication.
- Versioning mechanism (Vector Clock) to handle data consistency issues.
- Quorum and decentralized synchronization protocols to maintain consistency among replicas (Merkle Tree).
- Gossip Protocol for failure detection and replica maintenance.
In terms of implementation, Dynamo has the following characteristics:
- Fully decentralized, with no central node; all nodes are peers.
- Adopts eventual consistency, using version numbers to resolve conflicts, even requiring users to participate in conflict resolution.
- Uses hash values for data partitioning, organizing data distribution, and balancing data load.